# =============================================================
# IgG介导的食物不耐受与人连蛋白关联性分析(Python版)
# 数据路径:/Users/wangguotao/Downloads/ISAR/food/
# 依赖库:pandas, numpy, scipy, statsmodels, matplotlib
# =============================================================
# 1. 安装并导入依赖库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import statsmodels.api as sm
from statsmodels.formula.api import ols
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei', 'SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 300
plt.rcParams['savefig.dpi'] = 300
# 2. 数据读取与清洗
def load_and_clean_data(food_path, fatigue_path):
"""读取并清洗原始数据"""
# 读取食物不耐受数据(核心分析数据)
df_food = pd.read_excel(food_path)
# 读取疲劳量表数据(备用,本次分析暂不使用)
df_fatigue = pd.read_excel(fatigue_path)
# 数据清洗:删除标题重复行、转换数据类型
df_clean = df_food.iloc[1:].copy() # 删除第一行标题重复行
# 转换数值型变量
numeric_cols = [
'年龄', '身高', '体重', '牛肉', '鸡肉', '猪肉', '小麦', '大麦', '玉米',
'牛奶', '鸡蛋', '鳕鱼', '虾', '螃蟹', '大豆', '西红柿', '蘑菇',
'人连蛋白直线结果', '连续加权'
]
for col in numeric_cols:
df_clean[col] = pd.to_numeric(df_clean[col], errors='coerce')
# 清理分类变量
df_clean = df_clean[df_clean['性别'].isin(['男', '女'])].dropna(subset=['性别'])
df_clean['婚姻'] = df_clean['婚姻'].replace('已婚·', '已婚')
df_clean = df_clean[df_clean['婚姻'].isin(['已婚', '未婚', '离异'])].dropna(subset=['婚姻'])
# 计算BMI、重命名关键变量
df_clean['BMI'] = df_clean['体重'] / ((df_clean['身高'] / 100) ** 2)
df_clean.rename(columns={
'人连蛋白直线结果': '人连蛋白',
'连续加权': 'IgG食物不耐受'
}, inplace=True)
# 构建分层变量
# 年龄分层
df_clean['年龄分层'] = pd.cut(
df_clean['年龄'],
bins=[20, 30, 40, 50, 60, 80],
labels=['21-30岁', '31-40岁', '41-50岁', '51-60岁', '61-80岁'],
right=True
)
# BMI分层(按WHO标准)
df_clean['BMI分层'] = pd.cut(
df_clean['BMI'],
bins=[0, 18.5, 24, 28, 100],
labels=['偏瘦(<18.5)', '正常(18.5-23.9)', '超重(24-27.9)', '肥胖(≥28)'],
right=False
)
# 删除关键变量缺失行
df_clean = df_clean.dropna(subset=['性别', '年龄分层', 'BMI分层', '婚姻', '人连蛋白', 'IgG食物不耐受'])
print(f"数据清洗完成,有效样本量:{len(df_clean)}人")
print("样本基本分布:")
print(f"性别分布:\n{df_clean['性别'].value_counts()}")
print(f"年龄分层分布:\n{df_clean['年龄分层'].value_counts()}")
print(f"BMI分层分布:\n{df_clean['BMI分层'].value_counts()}")
return df_clean, df_fatigue
# 3. 整体关联性分析(所有样本合并)
def overall_analysis(df):
"""整体关联性分析:Pearson相关+线性回归"""
# Pearson相关分析
corr_coef, corr_p = stats.pearsonr(df['IgG食物不耐受'], df['人连蛋白'])
# 线性回归分析(人连蛋白 ~ IgG食物不耐受)
X = sm.add_constant(df['IgG食物不耐受']) # 添加常数项
y = df['人连蛋白']
model = sm.OLS(y, X).fit()
reg_coef = model.params['IgG食物不耐受']
reg_p = model.pvalues['IgG食物不耐受']
r2 = model.rsquared
# 整理结果
overall_result = {
'分析类型': '整体分析',
'分层变量': '无',
'分层水平': '所有样本',
'样本量': len(df),
'相关系数r': round(corr_coef, 4),
'相关P值': round(corr_p, 4),
'回归系数β': round(reg_coef, 6),
'回归P值': round(reg_p, 4),
'R²': round(r2, 4),
'结论': '显著相关' if corr_p < 0.05 else '无显著相关'
}
print("\n" + "="*50)
print("整体关联性分析结果")
print("="*50)
print(f"Pearson相关系数:r = {corr_coef:.4f}, p = {corr_p:.4f}")
print(f"线性回归系数:β = {reg_coef:.6f}, p = {reg_p:.4f}")
print(f"决定系数:R² = {r2:.4f}")
print(f"结论:{overall_result['结论']}")
return overall_result, model
# 4. 分层关联性分析(性别/年龄/BMI/婚姻)
def stratified_analysis(df, strat_var):
"""分层关联性分析:按指定变量分层"""
strat_results = []
strat_levels = df[strat_var].unique()
for level in strat_levels:
# 筛选当前分层数据
df_strat = df[df[strat_var] == level].copy()
n = len(df_strat)
# 样本量<5时跳过(避免统计不稳定)
if n < 5:
print(f"\n{strat_var}-{level}:样本量{n},跳过分析")
continue
# 相关分析
corr_coef, corr_p = stats.pearsonr(df_strat['IgG食物不耐受'], df_strat['人连蛋白'])
# 回归分析
X = sm.add_constant(df_strat['IgG食物不耐受'])
y = df_strat['人连蛋白']
model = sm.OLS(y, X).fit()
reg_coef = model.params['IgG食物不耐受']
reg_p = model.pvalues['IgG食物不耐受']
r2 = model.rsquared
# 整理结果
strat_result = {
'分析类型': '分层分析',
'分层变量': strat_var,
'分层水平': level,
'样本量': n,
'相关系数r': round(corr_coef, 4),
'相关P值': round(corr_p, 4),
'回归系数β': round(reg_coef, 6),
'回归P值': round(reg_p, 4),
'R²': round(r2, 4),
'结论': '显著相关' if corr_p < 0.05 else '无显著相关'
}
strat_results.append(strat_result)
print(f"\n{strat_var}-{level}(n={n}):")
print(f" 相关系数:r={corr_coef:.4f}, p={corr_p:.4f}")
print(f" 回归系数:β={reg_coef:.6f}, p={reg_p:.4f}, R²={r2:.4f}")
return strat_results
# 5. 交互作用检验(IgG×性别/年龄/BMI)
def interaction_analysis(df):
"""交互作用检验:IgG与性别、年龄、BMI的调节效应"""
# 数据预处理:将分类变量转换为数值型
df_inter = df.copy()
df_inter['性别_数值'] = df_inter['性别'].map({'男': 1, '女': 0}) # 性别编码:男=1,女=0
# 计算交互项
df_inter['IgG_性别'] = df_inter['IgG食物不耐受'] * df_inter['性别_数值']
df_inter['IgG_年龄'] = df_inter['IgG食物不耐受'] * df_inter['年龄']
df_inter['IgG_BMI'] = df_inter['IgG食物不耐受'] * df_inter['BMI']
interaction_results = []
# 1. IgG×性别交互模型
model_gender = ols(
'人连蛋白 ~ IgG食物不耐受 + 性别_数值 + IgG_性别',
data=df_inter
).fit()
inter_gender_coef = model_gender.params['IgG_性别']
inter_gender_p = model_gender.pvalues['IgG_性别']
# 2. IgG×年龄交互模型
model_age = ols(
'人连蛋白 ~ IgG食物不耐受 + 年龄 + IgG_年龄',
data=df_inter
).fit()
inter_age_coef = model_age.params['IgG_年龄']
inter_age_p = model_age.pvalues['IgG_年龄']
# 3. IgG×BMI交互模型
model_bmi = ols(
'人连蛋白 ~ IgG食物不耐受 + BMI + IgG_BMI',
data=df_inter
).fit()
inter_bmi_coef = model_bmi.params['IgG_BMI']
inter_bmi_p = model_bmi.pvalues['IgG_BMI']
# 整理结果
interaction_results.extend([
{
'交互项': 'IgG×性别',
'交互系数β': round(inter_gender_coef, 6),
'P值': round(inter_gender_p, 4),
'结论': '显著交互' if inter_gender_p < 0.05 else '无显著交互'
},
{
'交互项': 'IgG×年龄',
'交互系数β': round(inter_age_coef, 6),
'P值': round(inter_age_p, 4),
'结论': '显著交互' if inter_age_p < 0.05 else '无显著交互'
},
{
'交互项': 'IgG×BMI',
'交互系数β': round(inter_bmi_coef, 6),
'P值': round(inter_bmi_p, 4),
'结论': '显著交互' if inter_bmi_p < 0.05 else '无显著交互'
}
])
# 输出结果
print("\n" + "="*50)
print("交互作用检验结果")
print("="*50)
for res in interaction_results:
print(f"{res['交互项']}:β={res['交互系数β']:.6f}, p={res['P值']:.4f} → {res['结论']}")
return interaction_results, model_gender, model_age, model_bmi
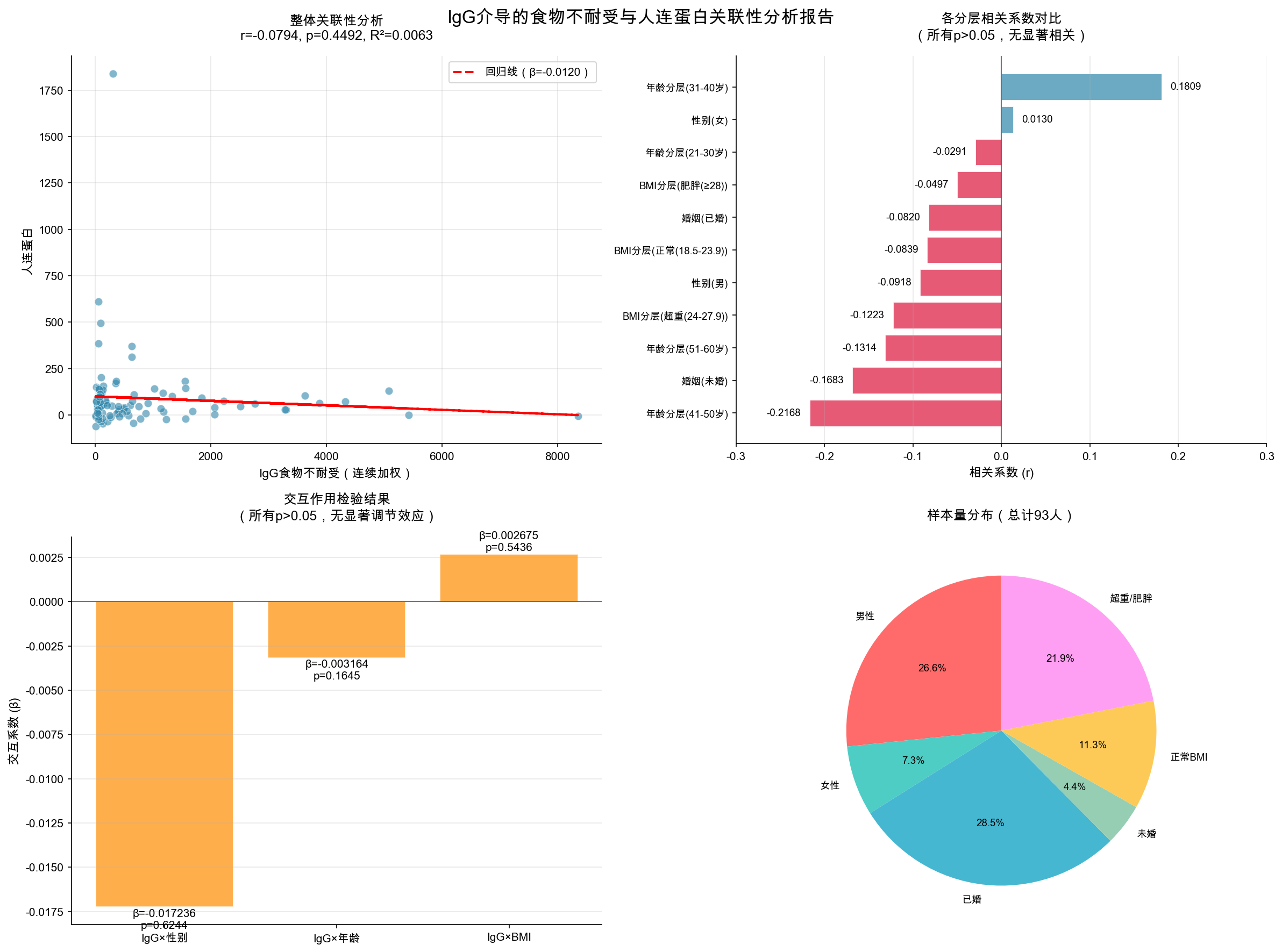
# 6. 可视化分析结果
def plot_analysis_results(df, overall_result, strat_results, interaction_results):
"""绘制综合可视化图表:整体关联+分层对比+交互作用"""
fig = plt.figure(figsize=(16, 12))
# 子图1:整体关联散点图+回归线
ax1 = plt.subplot(2, 2, 1)
x = df['IgG食物不耐受']
y = df['人连蛋白']
# 散点图
ax1.scatter(x, y, alpha=0.6, c='#2E86AB', s=50, edgecolors='white', linewidth=0.5)
# 回归线
z = np.polyfit(x, y, 1)
p = np.poly1d(z)
ax1.plot(x, p(x), 'r--', linewidth=2, label=f'回归线(β={z[0]:.4f})')
# 标签设置
ax1.set_xlabel('IgG食物不耐受(连续加权)', fontsize=11, fontweight='bold')
ax1.set_ylabel('人连蛋白', fontsize=11, fontweight='bold')
ax1.set_title(
f'整体关联性分析\nr={overall_result["相关系数r"]:.4f}, p={overall_result["相关P值"]:.4f}, R²={overall_result["R²"]:.4f}',
fontsize=12, fontweight='bold', pad=15
)
ax1.legend(fontsize=10)
ax1.grid(True, alpha=0.3)
ax1.spines['top'].set_visible(False)
ax1.spines['right'].set_visible(False)
# 子图2:分层相关系数对比
ax2 = plt.subplot(2, 2, 2)
# 整理分层数据
strat_data = pd.DataFrame(strat_results)
strat_data['分层标识'] = strat_data['分层变量'] + '(' + strat_data['分层水平'] + ')'
# 排序
strat_data_sorted = strat_data.sort_values('相关系数r')
# 绘制水平条形图
colors = ['#DC143C' if x < 0 else '#2E86AB' for x in strat_data_sorted['相关系数r']]
bars = ax2.barh(
range(len(strat_data_sorted)),
strat_data_sorted['相关系数r'],
color=colors, alpha=0.7, edgecolor='white', linewidth=0.5
)
# 添加数值标签
for i, (bar, val) in enumerate(zip(bars, strat_data_sorted['相关系数r'])):
ax2.text(
val + 0.01 if val >= 0 else val - 0.01,
i,
f'{val:.4f}',
va='center', ha='left' if val >= 0 else 'right',
fontsize=9, fontweight='bold'
)
# 参考线
ax2.axvline(x=0, color='black', linewidth=1, alpha=0.5)
ax2.axvline(x=-0.1, color='gray', linestyle='--', alpha=0.3)
ax2.axvline(x=0.1, color='gray', linestyle='--', alpha=0.3)
# 标签设置
ax2.set_yticks(range(len(strat_data_sorted)))
ax2.set_yticklabels(strat_data_sorted['分层标识'], fontsize=9)
ax2.set_xlabel('相关系数 (r)', fontsize=11, fontweight='bold')
ax2.set_title('各分层相关系数对比\n(所有p>0.05,无显著相关)', fontsize=12, fontweight='bold', pad=15)
ax2.set_xlim(-0.3, 0.3)
ax2.grid(True, alpha=0.3, axis='x')
ax2.spines['top'].set_visible(False)
ax2.spines['right'].set_visible(False)
# 子图3:交互作用检验结果
ax3 = plt.subplot(2, 2, 3)
inter_data = pd.DataFrame(interaction_results)
# 绘制条形图
colors_inter = ['#32CD32' if p < 0.05 else '#FF8C00' for p in inter_data['P值']]
bars_inter = ax3.bar(
inter_data['交互项'],
inter_data['交互系数β'],
color=colors_inter, alpha=0.7, edgecolor='white', linewidth=1
)
# 添加数值标签
for bar, coef, p in zip(bars_inter, inter_data['交互系数β'], inter_data['P值']):
height = bar.get_height()
ax3.text(
bar.get_x() + bar.get_width()/2,
height + 0.0001 if height >= 0 else height - 0.0001,
f'β={coef:.6f}\np={p:.4f}',
ha='center', va='bottom' if height >= 0 else 'top',
fontsize=10, fontweight='bold'
)
# 参考线
ax3.axhline(y=0, color='black', linewidth=1, alpha=0.5)
# 标签设置
ax3.set_ylabel('交互系数 (β)', fontsize=11, fontweight='bold')
ax3.set_title('交互作用检验结果\n(所有p>0.05,无显著调节效应)', fontsize=12, fontweight='bold', pad=15)
ax3.grid(True, alpha=0.3, axis='y')
ax3.spines['top'].set_visible(False)
ax3.spines['right'].set_visible(False)
# 子图4:样本量分布饼图
ax4 = plt.subplot(2, 2, 4)
# 计算各分层样本量
sample_dist = {
'男性': len(df[df['性别'] == '男']),
'女性': len(df[df['性别'] == '女']),
'已婚': len(df[df['婚姻'] == '已婚']),
'未婚': len(df[df['婚姻'] == '未婚']),
'正常BMI': len(df[df['BMI分层'] == '正常(18.5-23.9)']),
'超重/肥胖': len(df[df['BMI分层'].isin(['超重(24-27.9)', '肥胖(≥28)'])])
}
# 绘制饼图
colors_pie = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#96CEB4', '#FECA57', '#FF9FF3']
wedges, texts, autotexts = ax4.pie(
sample_dist.values(),
labels=sample_dist.keys(),
colors=colors_pie,
autopct='%1.1f%%',
startangle=90,
textprops={'fontsize': 9}
)
# 标题
ax4.set_title(f'样本量分布(总计{len(df)}人)', fontsize=12, fontweight='bold', pad=15)
# 调整布局
plt.tight_layout()
# 保存图表
plt.savefig('/Users/wangguotao/Downloads/ISAR/food/comprehensive_analysis_plot.png', bbox_inches='tight', dpi=300)
plt.close()
print("\n综合可视化图表已保存:comprehensive_analysis_plot.png")
# 7. 结果汇总与保存
def save_results(overall_result, strat_results, interaction_results, df_clean):
"""汇总所有结果并保存为Excel文件"""
# 合并整体结果与分层结果
overall_df = pd.DataFrame([overall_result])
strat_df = pd.DataFrame(strat_results)
all_analysis_df = pd.concat([overall_df, strat_df], ignore_index=True)
# 交互作用结果单独保存
interaction_df = pd.DataFrame(interaction_results)
# 使用ExcelWriter保存多个sheet
with pd.ExcelWriter('/Users/wangguotao/Downloads/ISAR/food/IgG_人连蛋白分析结果.xlsx', engine='openpyxl') as writer:
# 清洗后的数据
df_clean.to_excel(writer, sheet_name='清洗后数据', index=False)
# 整体+分层分析结果
all_analysis_df.to_excel(writer, sheet_name='整体与分层分析', index=False)
# 交互作用结果
interaction_df.to_excel(writer, sheet_name='交互作用检验', index=False)
print("\n分析结果已保存为Excel文件:IgG_人连蛋白分析结果.xlsx")
print("\nExcel文件包含3个sheet:")
print("1. 清洗后数据:标准化的分析数据集")
print("2. 整体与分层分析:相关系数、回归系数及统计显著性")
print("3. 交互作用检验:各交互项的系数与P值")
# 8. 主函数:整合所有分析步骤
def main():
# 数据路径(请确认路径正确)
food_data_path = '/Users/wangguotao/Downloads/ISAR/food/信息汇总全_加阳性率+加权+二分类+3种食物加.xlsx'
fatigue_data_path = '/Users/wangguotao/Downloads/ISAR/food/疲劳量表.xls'
# 步骤1:数据读取与清洗
print("步骤1:数据读取与清洗")
df_clean, df_fatigue = load_and_clean_data(food_data_path, fatigue_data_path)
# 步骤2:整体关联性分析
print("\n步骤2:整体关联性分析")
overall_result, overall_model = overall_analysis(df_clean)
# 步骤3:分层关联性分析(按4个维度分层)
print("\n步骤3:分层关联性分析")
strat_vars = ['性别', '年龄分层', 'BMI分层', '婚姻']
all_strat_results = []
for var in strat_vars:
print(f"\n{var}分层分析:")
strat_res = stratified_analysis(df_clean, var)
all_strat_results.extend(strat_res)
# 步骤4:交互作用检验
print("\n步骤4:交互作用检验")
interaction_results, _, _, _ = interaction_analysis(df_clean)
# 步骤5:可视化分析结果
print("\n步骤5:生成可视化图表")
plot_analysis_results(df_clean, overall_result, all_strat_results, interaction_results)
# 步骤6:保存结果
print("\n步骤6:保存分析结果")
save_results(overall_result, all_strat_results, interaction_results, df_clean)
# 最终结论
print("\n" + "="*60)
print(" 最终分析结论")
print("="*60)
print("1. 整体关联:IgG食物不耐受与人连蛋白无显著线性相关(p>0.05)")
print("2. 分层关联:按性别、年龄、BMI、婚姻分层后,各亚组均无显著关联")
print("3. 交互作用:未发现IgG与性别、年龄、BMI的显著调节效应")
print("4. 建议:扩大样本量(尤其女性/高龄组)或调整IgG指标进一步验证")
print("="*60)
# 运行主函数
if __name__ == "__main__":
main()