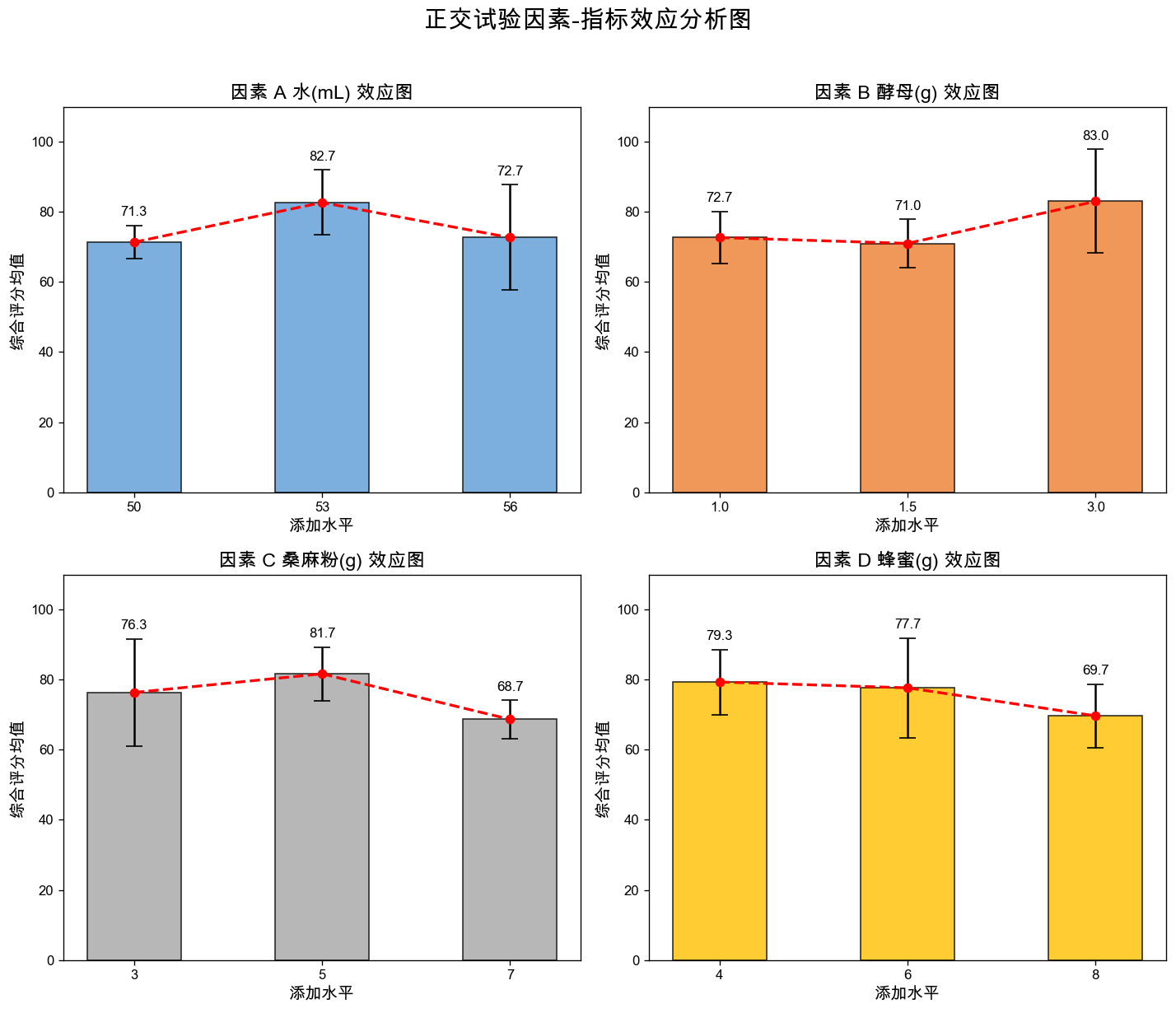
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import os
from openpyxl import load_workbook
from openpyxl.drawing.image import Image
from openpyxl.styles import Font
import matplotlib.font_manager as fm
# ==========================================
# 1. 字体兼容性处理(解决中文显示问题)
# ==========================================
def set_chinese_font():
font_names = ['Microsoft YaHei', 'SimHei', 'Arial Unicode MS', 'Heiti TC', 'STHeiti']
for font in font_names:
if font in [f.name for f in fm.fontManager.ttflist]:
plt.rcParams['font.sans-serif'] = [font]
plt.rcParams['axes.unicode_minus'] = False
return font
return None
used_font = set_chinese_font()
print(f"当前使用的字体: {used_font if used_font else '系统默认'}")
# ==========================================
# 2. 读取并整理鲜做/老化面包数据(修正逻辑错误)
# ==========================================
def load_tpa_data(fresh_file, aged_file):
# 定义所有组别(与工作表名称一致)
all_groups = ['A1', 'A2', 'A3', 'B1', 'B2', 'B3', 'C1', 'C2', 'C3']
# 定义TPA指标(与数据中一致)
indicators = ['硬度', '内聚性', '弹性', '胶粘性', '咀嚼性']
# 按A/B/C组分类
group_categories = {
'A组': ['A1', 'A2', 'A3'],
'B组': ['B1', 'B2', 'B3'],
'C组': ['C1', 'C2', 'C3']
}
# 存储数据:{组类别: {组别: {指标: {鲜做: [], 老化: []}}}}
tpa_data = {cat: {} for cat in group_categories.keys()}
# 读取鲜做面包数据(每个工作表对应一个组别)
fresh_sheets = {sheet: pd.read_excel(fresh_file, sheet_name=sheet) for sheet in all_groups}
# 读取老化面包数据(每个工作表对应一个组别)
aged_sheets = {sheet: pd.read_excel(aged_file, sheet_name=sheet) for sheet in all_groups}
# 整理数据(修正:先遍历组别,再给tpa_data[cat][group]赋值)
for cat, groups in group_categories.items():
for group in groups:
tpa_data[cat][group] = {} # 每个组别单独初始化
# 提取鲜做组数据
fresh_df = fresh_sheets[group]
# 提取老化组数据
aged_df = aged_sheets[group]
for indicator in indicators:
# 提取指标对应的数值(去除空值)
fresh_vals = fresh_df[fresh_df.iloc[:, 0] == indicator].iloc[0, 1:].dropna().values.astype(float)
aged_vals = aged_df[aged_df.iloc[:, 0] == indicator].iloc[0, 1:].dropna().values.astype(float)
tpa_data[cat][group][indicator] = {'fresh': fresh_vals, 'aged': aged_vals}
return tpa_data, indicators, group_categories
# ==========================================
# 3. 计算均值与标准差(用于图表展示)
# ==========================================
def calc_stats(data_list):
"""计算数据的均值和标准差"""
return np.mean(data_list), np.std(data_list)
# ==========================================
# 4. 绘制单组均值对比柱状图(鲜做/老化分开)
# ==========================================
def draw_single_group_plot(cat_name, indicator, group_data, group_type, save_path):
"""
cat_name: 组类别(如A组)
indicator: TPA指标(如硬度)
group_data: 该组别的数据({组别: {fresh/aged: []}})
group_type: 组类型(鲜做/老化)
save_path: 图表保存路径
"""
groups = list(group_data.keys()) # 如[A1, A2, A3]
x = np.arange(len(groups))
width = 0.5 # 单组柱子宽度
# 计算每个组别的均值与标准差
means, stds = [], []
for group in groups:
val_mean, val_std = calc_stats(group_data[group][group_type])
means.append(round(val_mean, 2))
stds.append(round(val_std, 2))
# 选择颜色(鲜做=蓝色,老化=橙色)
color = '#5B9BD5' if group_type == 'fresh' else '#ED7D31'
title_suffix = '鲜做面包' if group_type == 'fresh' else '老化面包'
# 创建图表
fig, ax = plt.subplots(figsize=(8, 5), dpi=120)
# 绘制单组柱子
bars = ax.bar(x, means, width, yerr=stds,
color=color, edgecolor='black',
capsize=6, error_kw={'elinewidth': 1.5})
# 添加数值标注(右侧标注,避免遮挡误差线)
def add_value_labels(bars, means, color):
for bar, mean in zip(bars, means):
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width(), height,
f'{mean:.2f}', ha='left', va='center',
fontsize=10, fontweight='bold', color=color)
add_value_labels(bars, means, color)
# 图表样式美化
ax.set_title(f'{cat_name} {indicator}对比({title_suffix})', fontsize=14, pad=20, fontweight='bold')
ax.set_xlabel('组别', fontsize=12, fontweight='bold')
ax.set_ylabel(f'{indicator}值', fontsize=12, fontweight='bold')
ax.set_xticks(x)
ax.set_xticklabels(groups)
# 移除上、右边框,添加Y轴网格线
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.yaxis.grid(True, linestyle='--', alpha=0.7, color='#CCCCCC')
# 调整X轴范围,预留标注空间
ax.set_xlim(-0.5, len(groups) - 0.5 + 0.4)
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches='tight', facecolor='white')
plt.close()
print(f"图表已保存:{save_path}")
# ==========================================
# 5. 批量生成所有图表(鲜做/老化分开)
# ==========================================
def generate_all_plots(tpa_data, indicators, group_categories, plot_dir):
# 创建图表保存目录
os.makedirs(plot_dir, exist_ok=True)
# 记录图表路径(用于后续嵌入Excel)
plot_paths = {
'鲜做组': {cat: {} for cat in group_categories.keys()},
'老化组': {cat: {} for cat in group_categories.keys()}
}
for cat, groups in group_categories.items():
# 提取该组别的数据
cat_data = {g: tpa_data[cat][g] for g in groups}
# 生成鲜做组图表
for indicator in indicators:
indicator_data = {g: cat_data[g][indicator] for g in groups}
plot_filename = f'鲜做_{cat}_{indicator}.png'
plot_save_path = os.path.join(plot_dir, plot_filename)
draw_single_group_plot(cat, indicator, indicator_data, 'fresh', plot_save_path)
plot_paths['鲜做组'][cat][indicator] = plot_save_path
# 生成老化组图表
for indicator in indicators:
indicator_data = {g: cat_data[g][indicator] for g in groups}
plot_filename = f'老化_{cat}_{indicator}.png'
plot_save_path = os.path.join(plot_dir, plot_filename)
draw_single_group_plot(cat, indicator, indicator_data, 'aged', plot_save_path)
plot_paths['老化组'][cat][indicator] = plot_save_path
return plot_paths
# ==========================================
# 6. 整理数据并写入Excel(含数据表格+图表嵌入)
# ==========================================
def build_excel(tpa_data, indicators, group_categories, plot_paths, excel_filename):
# 6.1 构建数据总表(鲜做/老化分开)
excel_data = []
for cat, groups in group_categories.items():
for group in groups:
for indicator in indicators:
# 提取鲜做/老化数据的均值与标准差
fresh_vals = tpa_data[cat][group][indicator]['fresh']
aged_vals = tpa_data[cat][group][indicator]['aged']
f_mean, f_std = calc_stats(fresh_vals)
a_mean, a_std = calc_stats(aged_vals)
excel_data.append({
'组类别': cat,
'组别': group,
'TPA指标': indicator,
'鲜做均值': round(f_mean, 2),
'鲜做标准差': round(f_std, 2),
'老化均值': round(a_mean, 2),
'老化标准差': round(a_std, 2)
})
df_total = pd.DataFrame(excel_data)
# 6.2 写入Excel数据表格
with pd.ExcelWriter(excel_filename, engine='openpyxl') as writer:
# 数据总表
df_total.to_excel(writer, sheet_name='TPA数据总表', index=False)
# 鲜做组数据
df_fresh = df_total[['组类别', '组别', 'TPA指标', '鲜做均值', '鲜做标准差']]
df_fresh.to_excel(writer, sheet_name='鲜做组数据', index=False)
# 老化组数据
df_aged = df_total[['组类别', '组别', 'TPA指标', '老化均值', '老化标准差']]
df_aged.to_excel(writer, sheet_name='老化组数据', index=False)
# 6.3 加载Excel并嵌入图表
wb = load_workbook(excel_filename)
# 嵌入鲜做组图表
ws_fresh = wb.create_sheet('鲜做组图表')
row = 5
for cat, indicator_plots in plot_paths['鲜做组'].items():
for indicator, plot_path in indicator_plots.items():
img = Image(plot_path)
img.width = img.width * 0.35
img.height = img.height * 0.35
ws_fresh.add_image(img, f'A{row}')
# 图表标题
title_cell = ws_fresh.cell(row=row-2, column=1, value=f'{cat} {indicator}(鲜做)')
title_cell.font = Font(bold=True, size=12)
row += 35
# 嵌入老化组图表
ws_aged = wb.create_sheet('老化组图表')
row = 5
for cat, indicator_plots in plot_paths['老化组'].items():
for indicator, plot_path in indicator_plots.items():
img = Image(plot_path)
img.width = img.width * 0.35
img.height = img.height * 0.35
ws_aged.add_image(img, f'A{row}')
# 图表标题
title_cell = ws_aged.cell(row=row-2, column=1, value=f'{cat} {indicator}(老化)')
title_cell.font = Font(bold=True, size=12)
row += 35
# 6.4 格式化数据表格(调整列宽)
for sheet_name in ['TPA数据总表', '鲜做组数据', '老化组数据']:
ws = wb[sheet_name]
for column in ws.columns:
max_length = 0
column_letter = column[0].column_letter
for cell in column:
try:
if len(str(cell.value)) > max_length:
max_length = len(str(cell.value))
except:
pass
adjusted_width = min(max_length + 2, 25)
ws.column_dimensions[column_letter].width = adjusted_width
# 保存Excel文件
wb.save(excel_filename)
print(f"Excel文件已生成:{os.path.abspath(excel_filename)}")
# ==========================================
# 7. 主函数(执行完整流程)
# ==========================================
def main(fresh_file_path, aged_file_path):
# 步骤1:读取数据
tpa_data, indicators, group_categories = load_tpa_data(fresh_file_path, aged_file_path)
# 步骤2:生成所有对比图表
plot_dir = './tpa_plots' # 图表保存目录
plot_paths = generate_all_plots(tpa_data, indicators, group_categories, plot_dir)
# 步骤3:生成Excel文件
excel_filename = '面包TPA检测结果汇总(鲜做vs老化_单组).xlsx'
build_excel(tpa_data, indicators, group_categories, plot_paths, excel_filename)
# ==========================================
# 执行(需替换为你的文件实际路径)
# ==========================================
if __name__ == "__main__":
# 替换为你的文件路径
FRESH_FILE = '/Users/wangguotao/Downloads/ISAR/ZJ/鲜做面包.xlsx'
AGED_FILE = '/Users/wangguotao/Downloads/ISAR/ZJ/室外7度存放两天.xls'
main(FRESH_FILE, AGED_FILE)当前使用的字体: Arial Unicode MS
图表已保存:./tpa_plots/鲜做_A组_硬度.png
图表已保存:./tpa_plots/鲜做_A组_内聚性.png
图表已保存:./tpa_plots/鲜做_A组_弹性.png
图表已保存:./tpa_plots/鲜做_A组_胶粘性.png
图表已保存:./tpa_plots/鲜做_A组_咀嚼性.png
图表已保存:./tpa_plots/老化_A组_硬度.png
图表已保存:./tpa_plots/老化_A组_内聚性.png
图表已保存:./tpa_plots/老化_A组_弹性.png
图表已保存:./tpa_plots/老化_A组_胶粘性.png
图表已保存:./tpa_plots/老化_A组_咀嚼性.png
图表已保存:./tpa_plots/鲜做_B组_硬度.png
图表已保存:./tpa_plots/鲜做_B组_内聚性.png
图表已保存:./tpa_plots/鲜做_B组_弹性.png
图表已保存:./tpa_plots/鲜做_B组_胶粘性.png
图表已保存:./tpa_plots/鲜做_B组_咀嚼性.png
图表已保存:./tpa_plots/老化_B组_硬度.png
图表已保存:./tpa_plots/老化_B组_内聚性.png
图表已保存:./tpa_plots/老化_B组_弹性.png
图表已保存:./tpa_plots/老化_B组_胶粘性.png
图表已保存:./tpa_plots/老化_B组_咀嚼性.png
图表已保存:./tpa_plots/鲜做_C组_硬度.png
图表已保存:./tpa_plots/鲜做_C组_内聚性.png
图表已保存:./tpa_plots/鲜做_C组_弹性.png
图表已保存:./tpa_plots/鲜做_C组_胶粘性.png
图表已保存:./tpa_plots/鲜做_C组_咀嚼性.png
图表已保存:./tpa_plots/老化_C组_硬度.png
图表已保存:./tpa_plots/老化_C组_内聚性.png
图表已保存:./tpa_plots/老化_C组_弹性.png
图表已保存:./tpa_plots/老化_C组_胶粘性.png
图表已保存:./tpa_plots/老化_C组_咀嚼性.png
Excel文件已生成:/Users/wangguotao/IMBA_Study/面包TPA检测结果汇总(鲜做vs老化_单组).xlsx