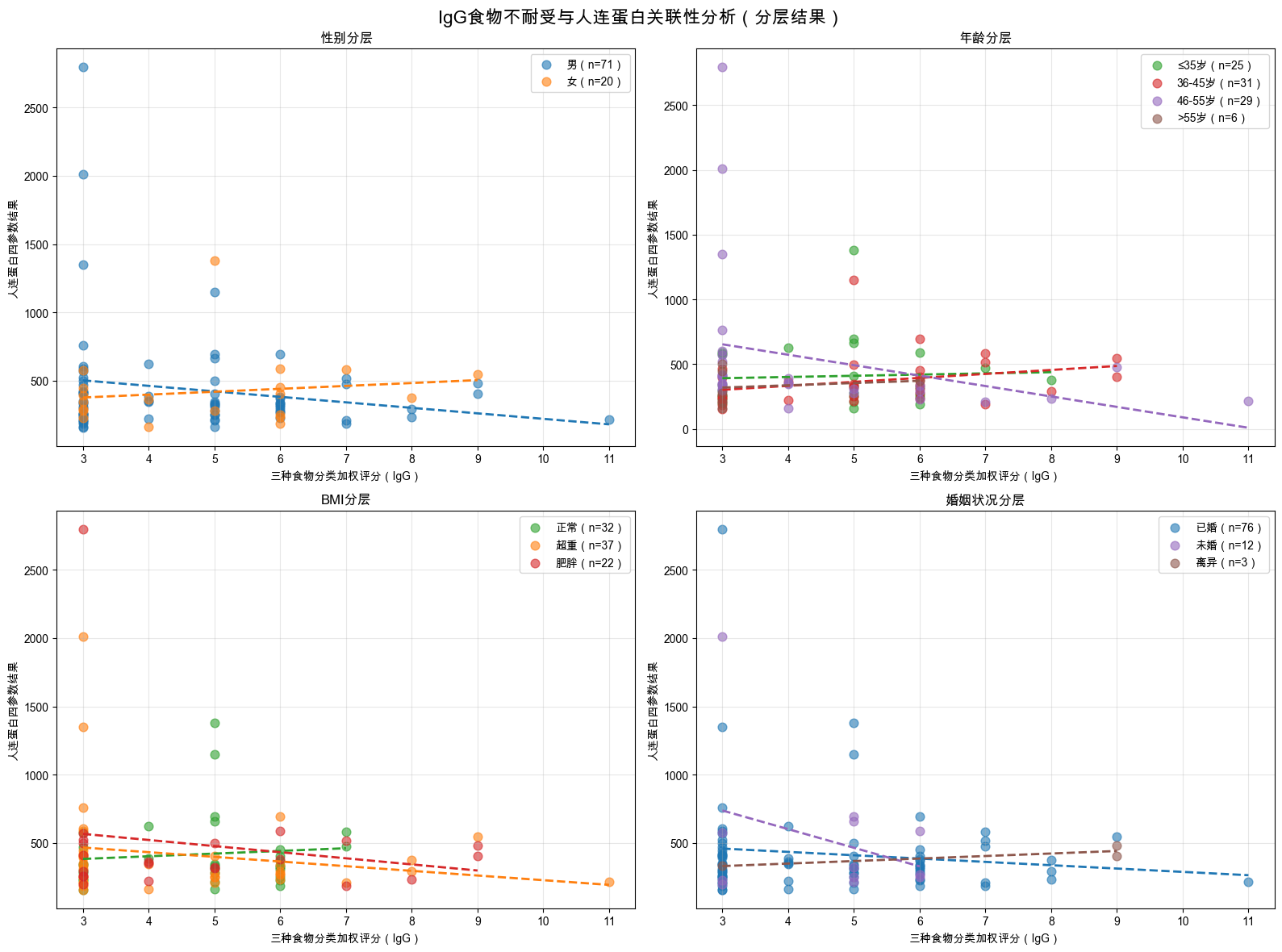
def export_results(gender_res=None, age_res=None, bmi_res=None, marriage_res=None, interaction_res=None):
"""将所有结果汇总到Excel文件(增加容错处理)"""
# 检查并定位缺失的变量
missing_vars = []
if gender_res is None:
missing_vars.append("性别分层结果(gender_res)")
if age_res is None:
missing_vars.append("年龄分层结果(age_res)")
if bmi_res is None:
missing_vars.append("BMI分层结果(bmi_res)")
if marriage_res is None:
missing_vars.append("婚姻分层结果(marriage_res)")
if interaction_res is None:
missing_vars.append("交互作用结果(interaction_res)")
# 如果关键分层结果都缺失,直接返回
if len(missing_vars) >= 4:
print(f"❌ 关键分析结果缺失过多:{', '.join(missing_vars)},无法生成Excel")
return
# 初始化Excel工作簿
wb = Workbook()
# 工作表1:性别分层(容错处理)
ws1 = wb.active
ws1.title = "性别分层"
ws1.append(['性别', '样本量', 'Pearson_r', 'Pearson_p', 'Spearman_r', 'Spearman_p', 'beta', 'beta_p', 'R2'])
if gender_res is not None:
for g, res in gender_res.items():
if '状态' not in res:
ws1.append([
g, res['样本量'], f"{res['Pearson_r']:.4f}", f"{res['Pearson_p']:.4f}",
f"{res['Spearman_r']:.4f}", f"{res['Spearman_p']:.4f}",
f"{res['beta']:.4f}", f"{res['beta_p']:.4f}", f"{res['R2']:.4f}"
])
else:
ws1.append(['无数据', '', '', '', '', '', '', '', ''])
# 工作表2:年龄分层(容错处理)
ws2 = wb.create_sheet("年龄分层")
ws2.append(['年龄组', '样本量', 'Pearson_r', 'Pearson_p', 'Spearman_r', 'Spearman_p', 'beta', 'beta_p', 'R2'])
if age_res is not None:
for a, res in age_res.items():
if '状态' not in res:
ws2.append([
a, res['样本量'], f"{res['Pearson_r']:.4f}", f"{res['Pearson_p']:.4f}",
f"{res['Spearman_r']:.4f}", f"{res['Spearman_p']:.4f}",
f"{res['beta']:.4f}", f"{res['beta_p']:.4f}", f"{res['R2']:.4f}"
])
else:
ws2.append(['无数据', '', '', '', '', '', '', '', ''])
# 工作表3:BMI分层(容错处理)
ws3 = wb.create_sheet("BMI分层")
ws3.append(['BMI分类', '样本量', 'Pearson_r', 'Pearson_p', 'Spearman_r', 'Spearman_p', 'beta', 'beta_p', 'R2'])
if bmi_res is not None:
for b, res in bmi_res.items():
if '状态' not in res:
ws3.append([
b, res['样本量'], f"{res['Pearson_r']:.4f}", f"{res['Pearson_p']:.4f}",
f"{res['Spearman_r']:.4f}", f"{res['Spearman_p']:.4f}",
f"{res['beta']:.4f}", f"{res['beta_p']:.4f}", f"{res['R2']:.4f}"
])
else:
ws3.append(['无数据', '', '', '', '', '', '', '', ''])
# 工作表4:婚姻分层(容错处理)
ws4 = wb.create_sheet("婚姻分层")
ws4.append(['婚姻状况', '样本量', 'Pearson_r', 'Pearson_p', 'Spearman_r', 'Spearman_p', 'beta', 'beta_p', 'R2'])
if marriage_res is not None:
for m, res in marriage_res.items():
if '状态' not in res:
ws4.append([
m, res['样本量'], f"{res['Pearson_r']:.4f}", f"{res['Pearson_p']:.4f}",
f"{res['Spearman_r']:.4f}", f"{res['Spearman_p']:.4f}",
f"{res['beta']:.4f}", f"{res['beta_p']:.4f}", f"{res['R2']:.4f}"
])
else:
ws4.append(['无数据', '', '', '', '', '', '', '', ''])
# 工作表5:交互作用检验(容错处理)
ws5 = wb.create_sheet("交互作用检验")
ws5.append(['检验项目', '数值', '显著性'])
if interaction_res is not None:
ws5.append(['模型1 R²', f"{interaction_res['model1'].rsquared:.4f}", '-'])
ws5.append(['模型1 F_p', f"{interaction_res['model1'].f_pvalue:.4f}",
'显著' if interaction_res['model1'].f_pvalue < 0.05 else '不显著'])
ws5.append(['模型2 R²', f"{interaction_res['model2'].rsquared:.4f}", '-'])
ws5.append(['模型2 F_p', f"{interaction_res['model2'].f_pvalue:.4f}",
'显著' if interaction_res['model2'].f_pvalue < 0.05 else '不显著'])
ws5.append(['ANOVA F', f"{interaction_res['anova_f']:.4f}", '-'])
ws5.append(['ANOVA p', f"{interaction_res['anova_p']:.4f}",
'显著' if interaction_res['anova_p'] < 0.05 else '不显著'])
for name, params in interaction_res['interaction_params'].items():
ws5.append([f"{name} p值", f"{params['p_val']:.4f}",
'显著' if params['p_val'] < 0.05 else '不显著'])
else:
ws5.append(['无交互作用分析数据', '', ''])
# 保存Excel文件
try:
excel_path = f"{OUTPUT_DIR}IgG人连蛋白分析结果汇总.xlsx"
wb.save(excel_path)
if missing_vars:
print(f"⚠️ Excel生成完成(部分数据缺失):{', '.join(missing_vars)}")
else:
print(f"✅ Excel生成完成")
print(f"💾 结果汇总Excel已保存:{excel_path}")
except Exception as e:
print(f"❌ Excel保存失败:{str(e)}")
# 执行结果导出(先检查变量是否存在,不存在则传None)
gender_res = locals().get('gender_res', None)
age_res = locals().get('age_res', None)
bmi_res = locals().get('bmi_res', None)
marriage_res = locals().get('marriage_res', None)
interaction_res = locals().get('interaction_res', None)
# 打印变量检查结果
print("🔍 导出前变量检查:")
print(f" gender_res: {'存在' if gender_res else '缺失'}")
print(f" age_res: {'存在' if age_res else '缺失'}")
print(f" bmi_res: {'存在' if bmi_res else '缺失'}")
print(f" marriage_res: {'存在' if marriage_res else '缺失'}")
print(f" interaction_res: {'存在' if interaction_res else '缺失'}")
# 调用导出函数
export_results(gender_res, age_res, bmi_res, marriage_res, interaction_res)