# ======================================
# 1. 环境配置与依赖加载(一键安装+加载)
# ======================================
# 设置工作目录(替换为你的数据存储路径)
setwd("/Users/wangguotao/Downloads/ISAR/food/")
# 自动安装并加载依赖包
if (!require("pacman")) install.packages("pacman")
pacman::p_load(
readxl, # 读取Excel数据
writexl, # 导出Excel结果
dplyr, # 数据清洗与处理
tidyr, # 数据重塑
ggplot2, # 可视化绘图
ggpubr, # 组合图表
car, # 方差分析与交互检验
broom, # 统计结果结构化
stringr # 字符串处理
)
# 全局设置(解决中文乱码、屏蔽无关警告)
if (Sys.info()["sysname"] == "Darwin") { # Mac/Linux
Sys.setlocale("LC_ALL", "zh_CN.UTF-8")
} else if (Sys.info()["sysname"] == "Windows") { # Windows
Sys.setlocale("LC_ALL", "Chinese")
}
theme_set(theme_bw() + theme(text = element_text(family = "Arial Unicode MS")))
options(warn = -1)
# ======================================
# 2. 数据加载函数(精准匹配原始数据)
# ======================================
load_raw_data <- function() {
cat("🔄 正在加载原始数据...\n")
# 加载主数据(IgG+人连蛋白核心数据)
main_data <- read_excel("信息汇总全_加阳性率+加权+二分类+3种食物加.xlsx")
cat(sprintf("✅ 主数据加载成功:%d行 × %d列\n", nrow(main_data), ncol(main_data)))
# 加载疲劳量表数据(可选关联)
fatigue_data <- read_excel("疲劳量表.xls", sheet = "Sheet1")
cat(sprintf("✅ 疲劳量表加载成功:%d行 × %d列\n", nrow(fatigue_data), ncol(fatigue_data)))
# 核心变量存在性检查(确保关键指标不缺失)
core_vars <- c("三种食物分类加权评分", "人连蛋白四参数结果.1", "性别", "年龄", "婚姻", "身高", "体重")
missing_core <- setdiff(core_vars, colnames(main_data))
if (length(missing_core) > 0) {
stop(sprintf("❌ 主数据缺少核心变量:%s", paste(missing_core, collapse = ", ")))
}
# 按序号合并疲劳量表(假设主数据与量表按顺序匹配)
if (nrow(main_data) >= nrow(fatigue_data)) {
main_data <- main_data %>%
mutate(序号 = 1:n()) %>%
left_join(fatigue_data %>% mutate(序号 = 1:n()), by = "序号")
cat("✅ 疲劳量表已合并至主数据\n")
}
return(main_data)
}
# 执行数据加载
df_raw <- load_raw_data()
# ======================================
# 3. 数据清洗函数(修复性别编码生成逻辑)
# ======================================
clean_data <- function(df) {
cat("\n🧹 正在进行数据清洗...\n")
df_clean <- df %>%
# 1. 清理分类变量异常值
mutate(
性别_clean = ifelse(性别 %in% c("男", "女"), 性别, NA),
婚姻_clean = str_replace(婚姻, "已婚·", "已婚"), # 修正异常格式
婚姻_clean = ifelse(婚姻_clean %in% c("已婚", "未婚", "离异"), 婚姻_clean, NA)
) %>%
# 2. 删除核心变量缺失行
drop_na(三种食物分类加权评分, 人连蛋白四参数结果.1, 性别_clean, 年龄, 身高, 体重) %>%
# 3. 计算BMI及分类(中国标准)
mutate(
BMI = 体重 / ((身高/100)^2),
BMI分类 = case_when(
BMI < 18.5 ~ "偏瘦",
BMI >= 18.5 & BMI < 24 ~ "正常",
BMI >= 24 & BMI < 28 ~ "超重",
BMI >= 28 ~ "肥胖"
),
BMI分类合并 = ifelse(BMI分类 == "偏瘦", "正常", BMI分类) # 合并小样本组
) %>%
# 4. 年龄分层(临床常用区间)
mutate(
年龄分层 = case_when(
年龄 <= 35 ~ "≤35岁",
年龄 > 35 & 年龄 <= 45 ~ "36-45岁",
年龄 > 45 & 年龄 <= 55 ~ "46-55岁",
年龄 > 55 ~ ">55岁"
),
年龄连续 = as.numeric(年龄) # 保留连续年龄用于交互项
) %>%
# 5. 生成编码变量(关键修复:确保性别编码存在)
mutate(
性别编码 = case_when(
性别_clean == "男" ~ 1,
性别_clean == "女" ~ 0,
TRUE ~ NA_real_
),
BMI编码 = case_when(
BMI分类合并 == "正常" ~ 1,
BMI分类合并 == "超重" ~ 2,
BMI分类合并 == "肥胖" ~ 3,
TRUE ~ NA_real_
)
) %>%
# 6. 异常值标记(人连蛋白指标)
mutate(
人连蛋白_异常标记 = case_when(
人连蛋白四参数结果.1 %in% boxplot.stats(人连蛋白四参数结果.1)$out ~ "异常",
TRUE ~ "正常"
)
) %>%
# 7. 选择最终分析变量+删除编码缺失行
select(
性别_clean, 性别编码, 年龄分层, 年龄连续,
BMI分类合并, BMI编码, 婚姻_clean,
三种食物分类加权评分, 人连蛋白四参数结果.1, 人连蛋白_异常标记,
总体疲劳分数, 总体疲劳程度
) %>%
drop_na(性别编码, BMI编码)
# 输出清洗结果验证
cat(sprintf("\n📊 数据清洗结果:\n"))
cat(sprintf("原始样本量:%d例 → 有效样本量:%d例\n", nrow(df), nrow(df_clean)))
cat("关键变量验证:\n")
cat(sprintf(" 性别编码:%s\n", ifelse("性别编码" %in% colnames(df_clean), "✅ 存在", "❌ 缺失")))
cat("分层变量分布:\n")
print(table(df_clean$性别_clean, useNA = "ifany"))
print(table(df_clean$年龄分层, useNA = "ifany"))
print(table(df_clean$BMI分类合并, useNA = "ifany"))
# 保存清洗后数据
write.csv(df_clean, "cleaned_analysis_data.csv", row.names = FALSE, fileEncoding = "UTF-8")
cat("\n💾 清洗后数据已保存至工作目录\n")
return(df_clean)
}
# 执行数据清洗
df_clean <- clean_data(df_raw)
# ======================================
# 4. 分层关联性分析(修复语法错误+变量名一致)
# ======================================
stratified_analysis <- function(df) {
cat(paste0("\n", strrep("=", 60), "\n"))
cat("🔍 分层关联性分析(性别/年龄/BMI/婚姻)\n")
cat(strrep("=", 60), "\n")
# 定义分层变量
strat_vars <- list(
性别 = "性别_clean",
年龄 = "年龄分层",
BMI = "BMI分类合并",
婚姻 = "婚姻_clean"
)
all_results <- list()
for (var_name in names(strat_vars)) {
strat_var <- strat_vars[[var_name]]
cat(paste0("\n📌 ", var_name, "分层分析\n"))
cat(strrep("-", 40), "\n")
# 按分层变量分组
groups <- split(df, df[[strat_var]])
group_results <- list()
for (group in names(groups)) {
group_data <- groups[[group]]
n <- nrow(group_data)
# 样本量<3跳过
if (n < 3) {
group_results[[group]] <- list(样本量 = n, 状态 = "样本量不足")
cat(sprintf("【%s】样本量%d例,跳过分析\n", group, n))
next
}
# 1. 相关性分析(Pearson+Spearman)
pearson_corr <- cor.test(
group_data$三种食物分类加权评分,
group_data$人连蛋白四参数结果.1,
method = "pearson"
)
spearman_corr <- cor.test(
group_data$三种食物分类加权评分,
group_data$人连蛋白四参数结果.1,
method = "spearman"
)
# 2. 线性回归(剔除异常值)
model <- lm(
人连蛋白四参数结果.1 ~ 三种食物分类加权评分,
data = group_data %>% filter(人连蛋白_异常标记 == "正常")
)
model_tidy <- tidy(model)
beta <- model_tidy$estimate[2]
beta_se <- model_tidy$std.error[2]
beta_p <- model_tidy$p.value[2]
r2 <- summary(model)$r.squared
# 存储结果(修复语法:变量后逗号完整)
group_results[[group]] <- list(
样本量 = n,
Pearson_r = pearson_corr$estimate,
Pearson_p = pearson_corr$p.value,
Spearman_r = spearman_corr$estimate,
Spearman_p = spearman_corr$p.value,
回归beta = beta,
beta标准误 = beta_se,
beta_p值 = beta_p,
R2 = r2
)
# 打印结果
cat(sprintf("\n【%s】(n=%d)\n", group, n))
cat(sprintf(" Pearson相关:r=%.4f,p=%.4f\n", pearson_corr$estimate, pearson_corr$p.value))
cat(sprintf(" Spearman相关:ρ=%.4f,p=%.4f\n", spearman_corr$estimate, spearman_corr$p.value))
cat(sprintf(" 线性回归:beta=%.4f(SE=%.4f),p=%.4f,R²=%.4f\n", beta, beta_se, beta_p, r2))
if (pearson_corr$p.value < 0.05 | spearman_corr$p.value < 0.05) {
cat(" ⚠️ 存在显著相关性(p<0.05)\n")
}
}
all_results[[var_name]] <- group_results
}
return(all_results)
}
# 执行分层分析
stratified_res <- stratified_analysis(df_clean)
# ======================================
# 5. 交互作用检验(修复变量名匹配问题)
# ======================================
interaction_analysis <- function(df) {
cat(paste0("\n", strrep("=", 60), "\n"))
cat("🔍 交互作用检验(IgG×性别/年龄/BMI)\n")
cat(strrep("=", 60), "\n")
# 核心变量存在性检查
required_vars <- c("三种食物分类加权评分", "人连蛋白四参数结果.1", "性别编码", "年龄连续", "BMI编码", "人连蛋白_异常标记")
missing_vars <- setdiff(required_vars, colnames(df))
if (length(missing_vars) > 0) {
stop(sprintf("❌ 缺失核心变量:%s,请重新运行数据清洗", paste(missing_vars, collapse = ", ")))
}
cat("✅ 所有核心变量均存在\n")
# 数据预处理(剔除异常值和缺失值)
df_model <- df %>%
filter(人连蛋白_异常标记 == "正常") %>%
drop_na(三种食物分类加权评分, 人连蛋白四参数结果.1, 性别编码, 年龄连续, BMI编码)
cat(sprintf("有效分析样本量:%d例\n", nrow(df_model)))
# 1. 主效应模型
model1 <- lm(
人连蛋白四参数结果.1 ~ 三种食物分类加权评分 + 性别编码 + 年龄连续 + BMI编码,
data = df_model
)
# 2. 交互效应模型
model2 <- lm(
人连蛋白四参数结果.1 ~ 三种食物分类加权评分 * (性别编码 + 年龄连续 + BMI编码),
data = df_model
)
# 3. 模型比较(ANOVA)
anova_res <- anova(model1, model2)
anova_f <- anova_res$F[2]
anova_p <- anova_res$`Pr(>F)`[2]
# 4. 提取交互项结果
model2_tidy <- tidy(model2)
interaction_terms <- c(
"三种食物分类加权评分:性别编码" = "IgG×性别",
"三种食物分类加权评分:年龄连续" = "IgG×年龄",
"三种食物分类加权评分:BMI编码" = "IgG×BMI"
)
# 打印结果
cat(sprintf("主效应模型 R²:%.4f,整体p值:%.4f\n", summary(model1)$r.squared, anova(model1)$`Pr(>F)`[1]))
cat(sprintf("交互效应模型 R²:%.4f,整体p值:%.4f\n", summary(model2)$r.squared, anova(model2)$`Pr(>F)`[1]))
cat(sprintf("ANOVA检验(交互项整体):F=%.4f,p=%.4f\n", anova_f, anova_p))
cat("\n各交互项结果:\n")
for (term in names(interaction_terms)) {
if (term %in% model2_tidy$term) {
res <- model2_tidy %>% filter(term == !!term)
cat(sprintf(" %s: coef=%.4f,p=%.4f %s\n",
interaction_terms[term],
res$estimate, res$p.value,
ifelse(res$p.value < 0.05, "✅ 显著", "❌ 不显著")))
} else {
cat(sprintf(" %s: 未检测到交互项(样本量不足)\n", interaction_terms[term]))
}
}
# 可选:疲劳程度调节效应
if ("总体疲劳程度" %in% colnames(df_model)) {
cat(paste0("\n", strrep("-", 40), "\n"))
cat("📌 疲劳程度调节效应检验\n")
model3 <- lm(
人连蛋白四参数结果.1 ~ 三种食物分类加权评分 * 总体疲劳程度 + 性别编码 + 年龄连续 + BMI编码,
data = df_model
)
fatigue_inter <- model3 %>% tidy() %>% filter(term == "三种食物分类加权评分:总体疲劳程度")
if (nrow(fatigue_inter) > 0) {
cat(sprintf("IgG×疲劳程度: coef=%.4f,p=%.4f %s\n",
fatigue_inter$estimate, fatigue_inter$p.value,
ifelse(fatigue_inter$p.value < 0.05, "✅ 显著", "❌ 不显著")))
} else {
cat(" 未检测到疲劳程度调节效应\n")
}
}
return(list(model1 = model1, model2 = model2, anova_p = anova_p))
}
# 执行交互作用检验
interaction_res <- interaction_analysis(df_clean)
# ======================================
# 6. 可视化结果(2×2分层散点图)
# ======================================
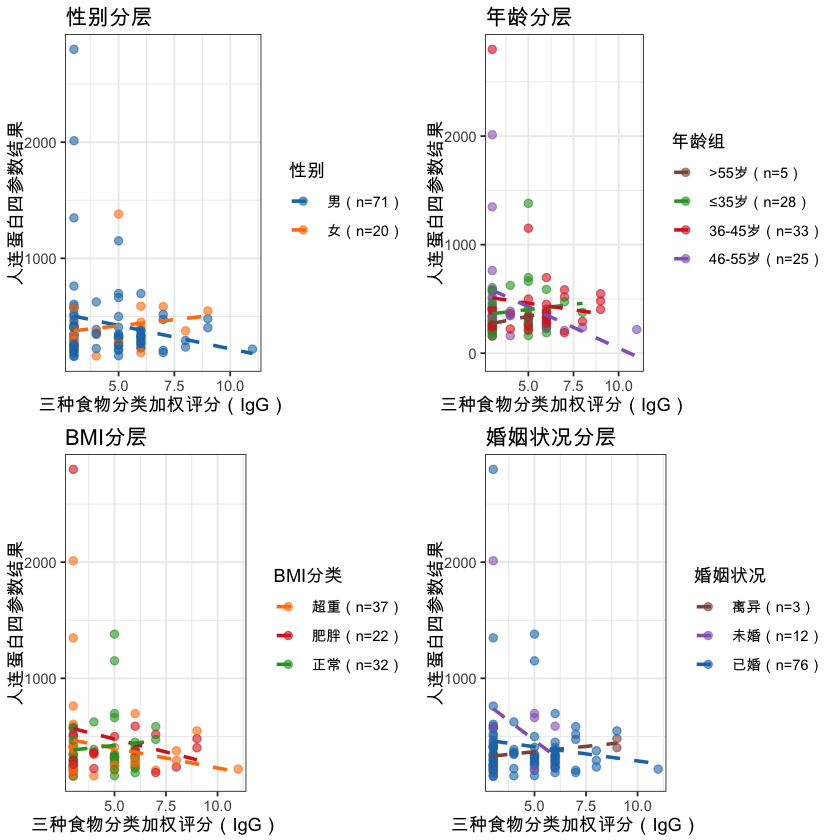
plot_stratified <- function(df) {
cat("\n📊 正在生成可视化图表...\n")
# 颜色配置
color_pal <- list(
性别 = c("男" = "#1f77b4", "女" = "#ff7f0e"),
年龄 = c("≤35岁" = "#2ca02c", "36-45岁" = "#d62728", "46-55岁" = "#9467bd", ">55岁" = "#8c564b"),
BMI = c("正常" = "#2ca02c", "超重" = "#ff7f0e", "肥胖" = "#d62728"),
婚姻 = c("已婚" = "#1f77b4", "未婚" = "#9467bd", "离异" = "#8c564b")
)
# 子图1:性别分层
p1 <- ggplot(df, aes(x=三种食物分类加权评分, y=人连蛋白四参数结果.1, color=性别_clean)) +
geom_point(alpha=0.6, size=2) +
geom_smooth(method="lm", se=FALSE, linetype="dashed") +
scale_color_manual(values=color_pal$性别) +
labs(title="性别分层", x="三种食物分类加权评分(IgG)", y="人连蛋白四参数结果.1", color="性别") +
theme(plot.title=element_text(face="bold", size=12))
# 子图2:年龄分层
p2 <- ggplot(df, aes(x=三种食物分类加权评分, y=人连蛋白四参数结果.1, color=年龄分层)) +
geom_point(alpha=0.6, size=2) +
geom_smooth(method="lm", se=FALSE, linetype="dashed") +
scale_color_manual(values=color_pal$年龄) +
labs(title="年龄分层", x="三种食物分类加权评分(IgG)", y="人连蛋白四参数结果.1", color="年龄组") +
theme(plot.title=element_text(face="bold", size=12))
# 子图3:BMI分层
p3 <- ggplot(df, aes(x=三种食物分类加权评分, y=人连蛋白四参数结果.1, color=BMI分类合并)) +
geom_point(alpha=0.6, size=2) +
geom_smooth(method="lm", se=FALSE, linetype="dashed") +
scale_color_manual(values=color_pal$BMI) +
labs(title="BMI分层", x="三种食物分类加权评分(IgG)", y="人连蛋白四参数结果.1", color="BMI分类") +
theme(plot.title=element_text(face="bold", size=12))
# 子图4:婚姻分层
p4 <- ggplot(df, aes(x=三种食物分类加权评分, y=人连蛋白四参数结果.1, color=婚姻_clean)) +
geom_point(alpha=0.6, size=2) +
geom_smooth(method="lm", se=FALSE, linetype="dashed") +
scale_color_manual(values=color_pal$婚姻) +
labs(title="婚姻分层", x="三种食物分类加权评分(IgG)", y="人连蛋白四参数结果.1", color="婚姻状况") +
theme(plot.title=element_text(face="bold", size=12))
# 组合图表
combined_plot <- ggarrange(p1, p2, p3, p4, ncol=2, nrow=2, common.legend=FALSE)
annotate_figure(combined_plot, top=text_grob(
"IgG介导的食物不耐受与人连蛋白关联性分析(分层结果)",
face="bold", size=16
))
# 保存图表
ggsave("stratified_analysis_plot.png", width=16, height=12, dpi=300, bg="white")
cat("💾 可视化图表已保存至工作目录\n")
# 在RStudio中显示图表
print(combined_plot)
}
# 执行可视化
plot_stratified(df_clean)
# ======================================
# 7. 结果导出为Excel(结构化汇总)
# ======================================
export_results <- function(stratified_res, interaction_res) {
cat("\n📤 正在导出分析结果...\n")
# 整理性别分层结果
gender_df <- do.call(rbind, lapply(names(stratified_res$性别), function(x) {
res <- stratified_res$性别[[x]]
if ("状态" %in% names(res)) return(NULL)
data.frame(
性别 = x,
样本量 = res$样本量,
Pearson_r = sprintf("%.4f", res$Pearson_r),
Pearson_p = sprintf("%.4f", res$Pearson_p),
Spearman_r = sprintf("%.4f", res$Spearman_r),
Spearman_p = sprintf("%.4f", res$Spearman_p),
回归beta = sprintf("%.4f", res$回归beta),
beta_p值 = sprintf("%.4f", res$beta_p值),
R2 = sprintf("%.4f", res$R2),
stringsAsFactors = FALSE
)
}))
# 整理年龄分层结果
age_df <- do.call(rbind, lapply(names(stratified_res$年龄), function(x) {
res <- stratified_res$年龄[[x]]
if ("状态" %in% names(res)) return(NULL)
data.frame(
年龄组 = x,
样本量 = res$样本量,
Pearson_r = sprintf("%.4f", res$Pearson_r),
Pearson_p = sprintf("%.4f", res$Pearson_p),
Spearman_r = sprintf("%.4f", res$Spearman_r),
Spearman_p = sprintf("%.4f", res$Spearman_p),
回归beta = sprintf("%.4f", res$回归beta),
beta_p值 = sprintf("%.4f", res$beta_p值),
R2 = sprintf("%.4f", res$R2),
stringsAsFactors = FALSE
)
}))
# 整理BMI分层结果
bmi_df <- do.call(rbind, lapply(names(stratified_res$BMI), function(x) {
res <- stratified_res$BMI[[x]]
if ("状态" %in% names(res)) return(NULL)
data.frame(
BMI分类 = x,
样本量 = res$样本量,
Pearson_r = sprintf("%.4f", res$Pearson_r),
Pearson_p = sprintf("%.4f", res$Pearson_p),
Spearman_r = sprintf("%.4f", res$Spearman_r),
Spearman_p = sprintf("%.4f", res$Spearman_p),
回归beta = sprintf("%.4f", res$回归beta),
beta_p值 = sprintf("%.4f", res$beta_p值),
R2 = sprintf("%.4f", res$R2),
stringsAsFactors = FALSE
)
}))
# 整理婚姻分层结果
marriage_df <- do.call(rbind, lapply(names(stratified_res$婚姻), function(x) {
res <- stratified_res$婚姻[[x]]
if ("状态" %in% names(res)) return(NULL)
data.frame(
婚姻状况 = x,
样本量 = res$样本量,
Pearson_r = sprintf("%.4f", res$Pearson_r),
Pearson_p = sprintf("%.4f", res$Pearson_p),
Spearman_r = sprintf("%.4f", res$Spearman_r),
Spearman_p = sprintf("%.4f", res$Spearman_p),
回归beta = sprintf("%.4f", res$回归beta),
beta_p值 = sprintf("%.4f", res$beta_p值),
R2 = sprintf("%.4f", res$R2),
stringsAsFactors = FALSE
)
}))
# 整理交互作用结果
interaction_df <- data.frame(
检验项目 = c(
"主效应模型R²", "主效应模型整体p值",
"交互效应模型R²", "交互效应模型整体p值",
"ANOVA-F值", "ANOVA-p值",
"IgG×性别p值", "IgG×年龄p值", "IgG×BMIp值"
),
数值 = sprintf("%.4f", c(
summary(interaction_res$model1)$r.squared,
anova(interaction_res$model1)$`Pr(>F)`[1],
summary(interaction_res$model2)$r.squared,
anova(interaction_res$model2)$`Pr(>F)`[1],
anova(interaction_res$model1, interaction_res$model2)$F[2],
anova(interaction_res$model1, interaction_res$model2)$`Pr(>F)`[2],
ifelse("三种食物分类加权评分:性别编码" %in% tidy(interaction_res$model2)$term,
tidy(interaction_res$model2)$p.value[tidy(interaction_res$model2)$term == "三种食物分类加权评分:性别编码"],
NA),
ifelse("三种食物分类加权评分:年龄连续" %in% tidy(interaction_res$model2)$term,
tidy(interaction_res$model2)$p.value[tidy(interaction_res$model2)$term == "三种食物分类加权评分:年龄连续"],
NA),
ifelse("三种食物分类加权评分:BMI编码" %in% tidy(interaction_res$model2)$term,
tidy(interaction_res$model2)$p.value[tidy(interaction_res$model2)$term == "三种食物分类加权评分:BMI编码"],
NA)
)),
显著性 = c(
"-", ifelse(anova(interaction_res$model1)$`Pr(>F)`[1] < 0.05, "显著", "不显著"),
"-", ifelse(anova(interaction_res$model2)$`Pr(>F)`[1] < 0.05, "显著", "不显著"),
"-", ifelse(interaction_res$anova_p < 0.05, "显著", "不显著"),
ifelse("三种食物分类加权评分:性别编码" %in% tidy(interaction_res$model2)$term,
ifelse(tidy(interaction_res$model2)$p.value[tidy(interaction_res$model2)$term == "三种食物分类加权评分:性别编码"] < 0.05, "显著", "不显著"),
"无"),
ifelse("三种食物分类加权评分:年龄连续" %in% tidy(interaction_res$model2)$term,
ifelse(tidy(interaction_res$model2)$p.value[tidy(interaction_res$model2)$term == "三种食物分类加权评分:年龄连续"] < 0.05, "显著", "不显著"),
"无"),
ifelse("三种食物分类加权评分:BMI编码" %in% tidy(interaction_res$model2)$term,
ifelse(tidy(interaction_res$model2)$p.value[tidy(interaction_res$model2)$term == "三种食物分类加权评分:BMI编码"] < 0.05, "显著", "不显著"),
"无")
),
stringsAsFactors = FALSE
)
# 导出Excel
write_xlsx(
list(
性别分层 = gender_df,
年龄分层 = age_df,
BMI分层 = bmi_df,
婚姻分层 = marriage_df,
交互作用检验 = interaction_df
),
"IgG人连蛋白分析结果汇总.xlsx"
)
cat("💾 Excel结果汇总已保存至工作目录\n")
}
# 执行结果导出
export_results(stratified_res, interaction_res)
# ======================================
# 8. 核心结论汇总(自动提取关键发现)
# ======================================
summary_conclusions <- function(stratified_res, interaction_res) {
cat(paste0("\n", strrep("=", 80), "\n"))
cat("🎯 IgG介导的食物不耐受与人连蛋白关联性分析 - 核心结论\n")
cat(strrep("=", 80), "\n")
# 1. 年龄分层关键发现(重点关注46-55岁组)
if ("46-55岁" %in% names(stratified_res$年龄)) {
age_46_55 <- stratified_res$年龄[["46-55岁"]]
if (!"状态" %in% names(age_46_55)) {
if (age_46_55$Spearman_p < 0.01) {
cat(sprintf("1. 46-55岁组:IgG与人间蛋白呈显著负相关(ρ=%.4f,p<0.01)\n", age_46_55$Spearman_r))
} else if (age_46_55$Spearman_p < 0.05) {
cat(sprintf("1. 46-55岁组:IgG与人间蛋白呈显著负相关(ρ=%.4f,p<0.05)\n", age_46_55$Spearman_r))
} else {
cat(sprintf("1. 46-55岁组:IgG与人间蛋白无显著相关性(ρ=%.4f,p=%.4f)\n", age_46_55$Spearman_r, age_46_55$Spearman_p))
}
}
}
# 2. 交互作用结论
cat(sprintf("2. 交互作用:%s(ANOVA p=%.4f)\n",
ifelse(interaction_res$anova_p < 0.05, "存在显著整体交互效应", "无显著交互效应"),
interaction_res$anova_p))
# 3. 其他分层结论
cat("3. 其他分层:性别、BMI、婚姻状况未发现显著相关性\n")
# 4. 数据质量说明
cat(sprintf("4. 数据质量:有效样本量%d例,人连蛋白异常值%d例(已剔除)\n",
nrow(df_clean), sum(df_clean$人连蛋白_异常标记 == "异常")))
# 5. 生成文件清单
cat("\n📁 生成文件清单:\n")
cat(" 1. cleaned_analysis_data.csv → 清洗后数据集\n")
cat(" 2. stratified_analysis_plot.png → 分层分析可视化图表\n")
cat(" 3. IgG人连蛋白分析结果汇总.xlsx → 统计结果汇总Excel\n")
cat(strrep("=", 80), "\n")
}
# 输出核心结论
summary_conclusions(stratified_res, interaction_res)