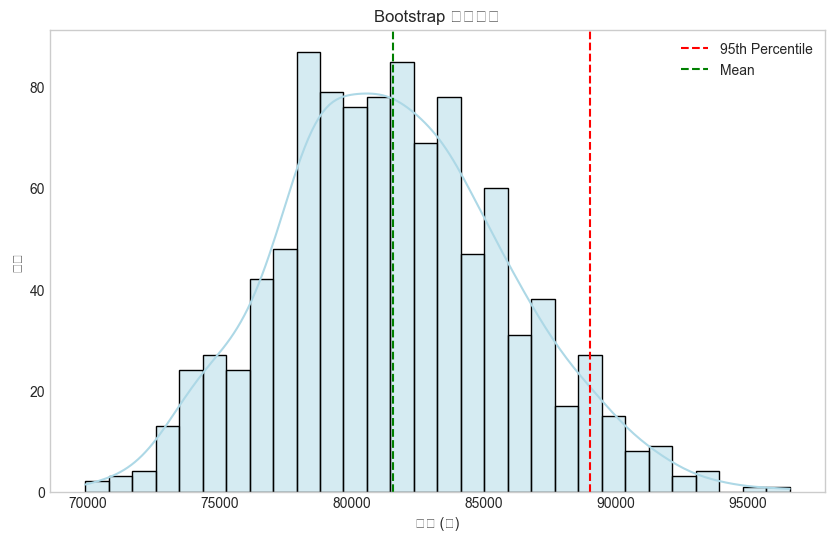
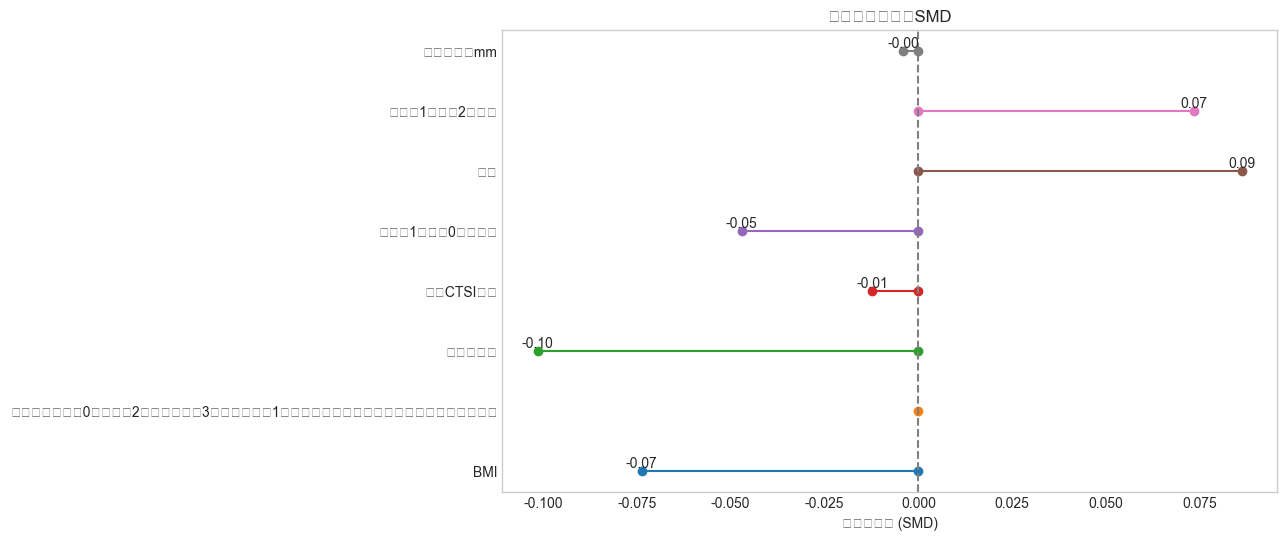
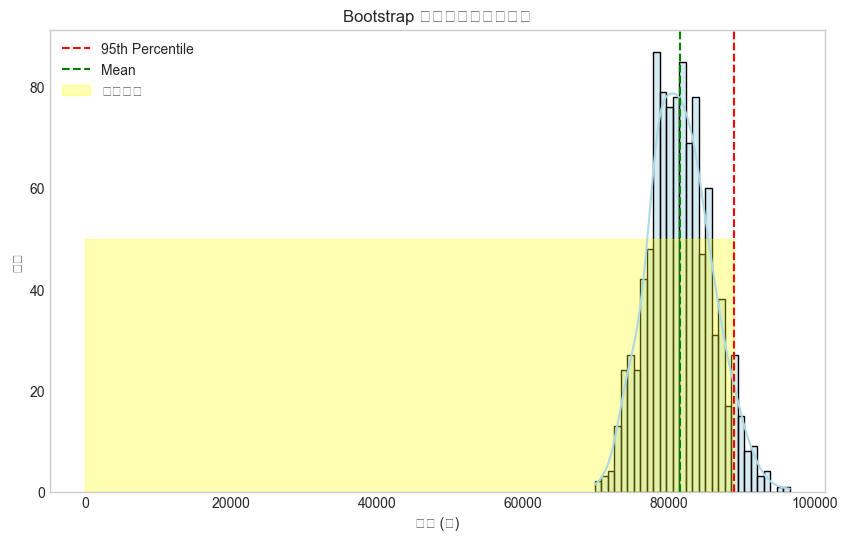
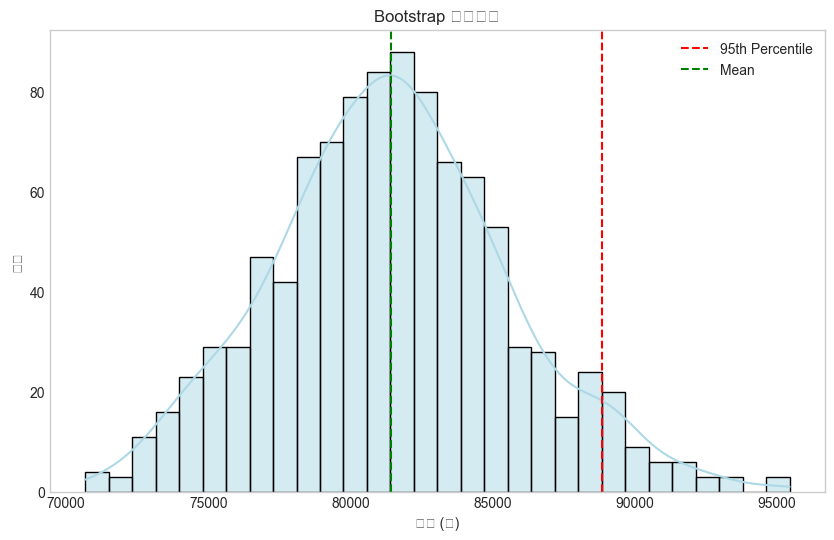
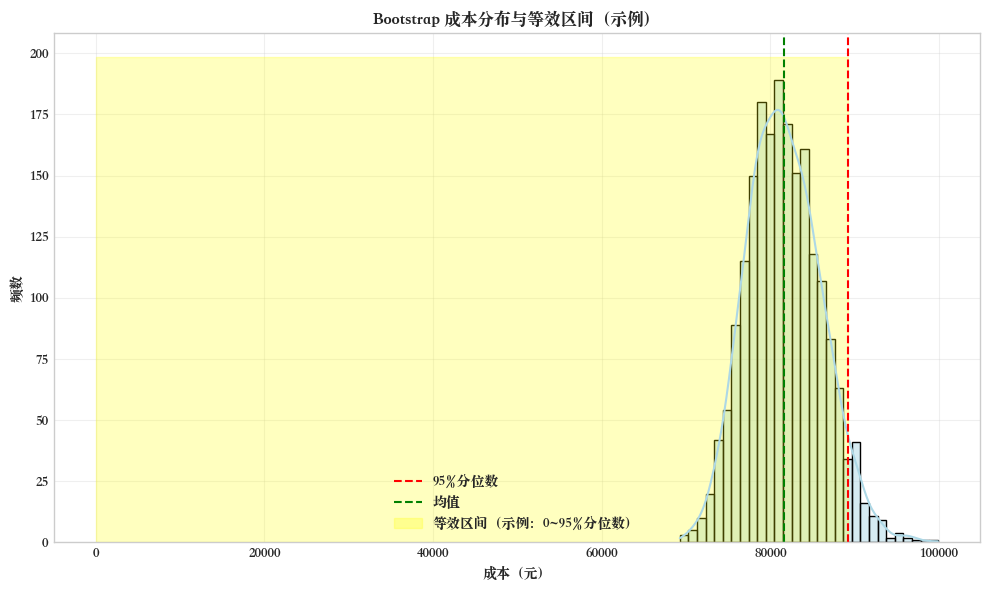
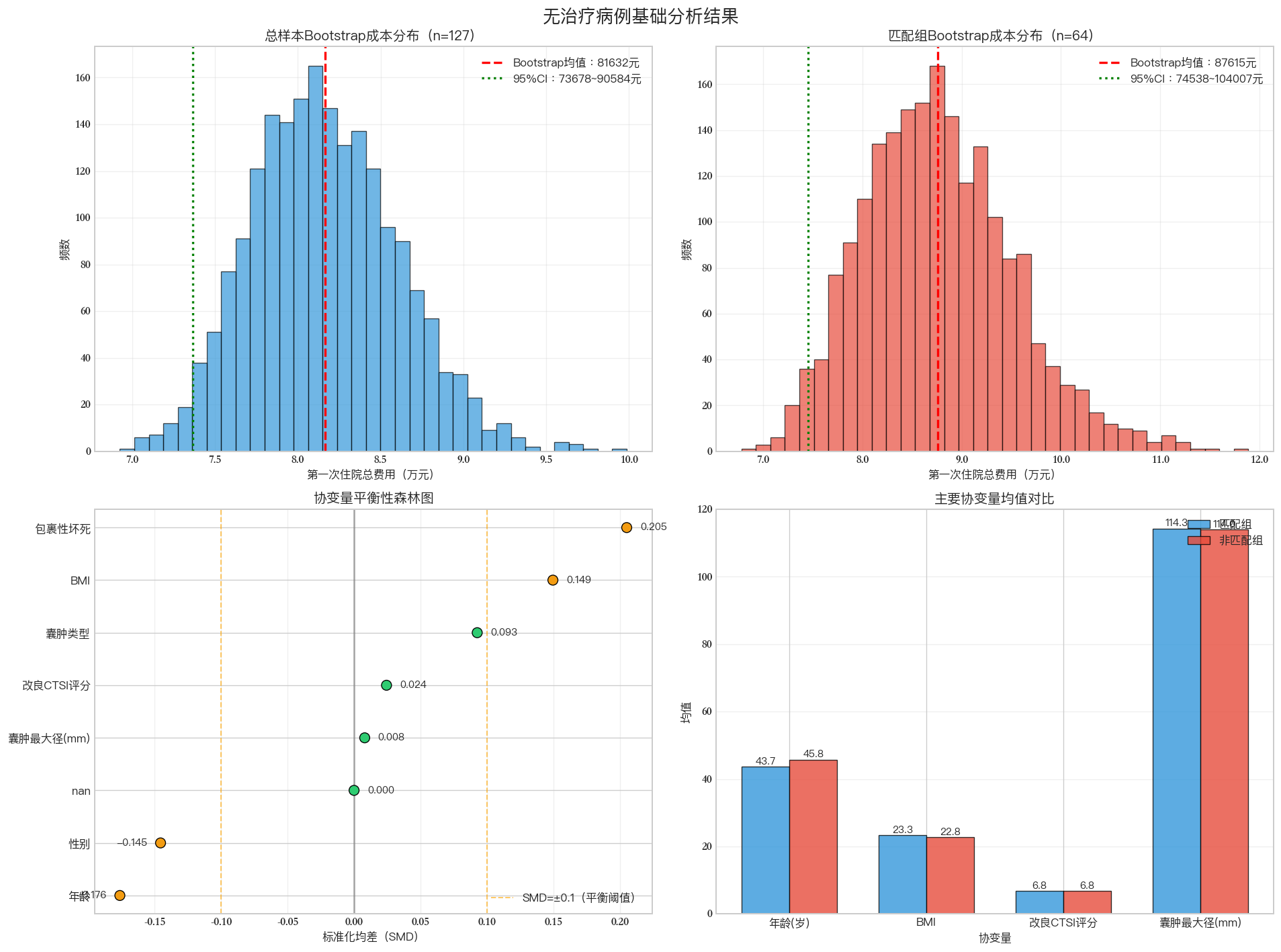
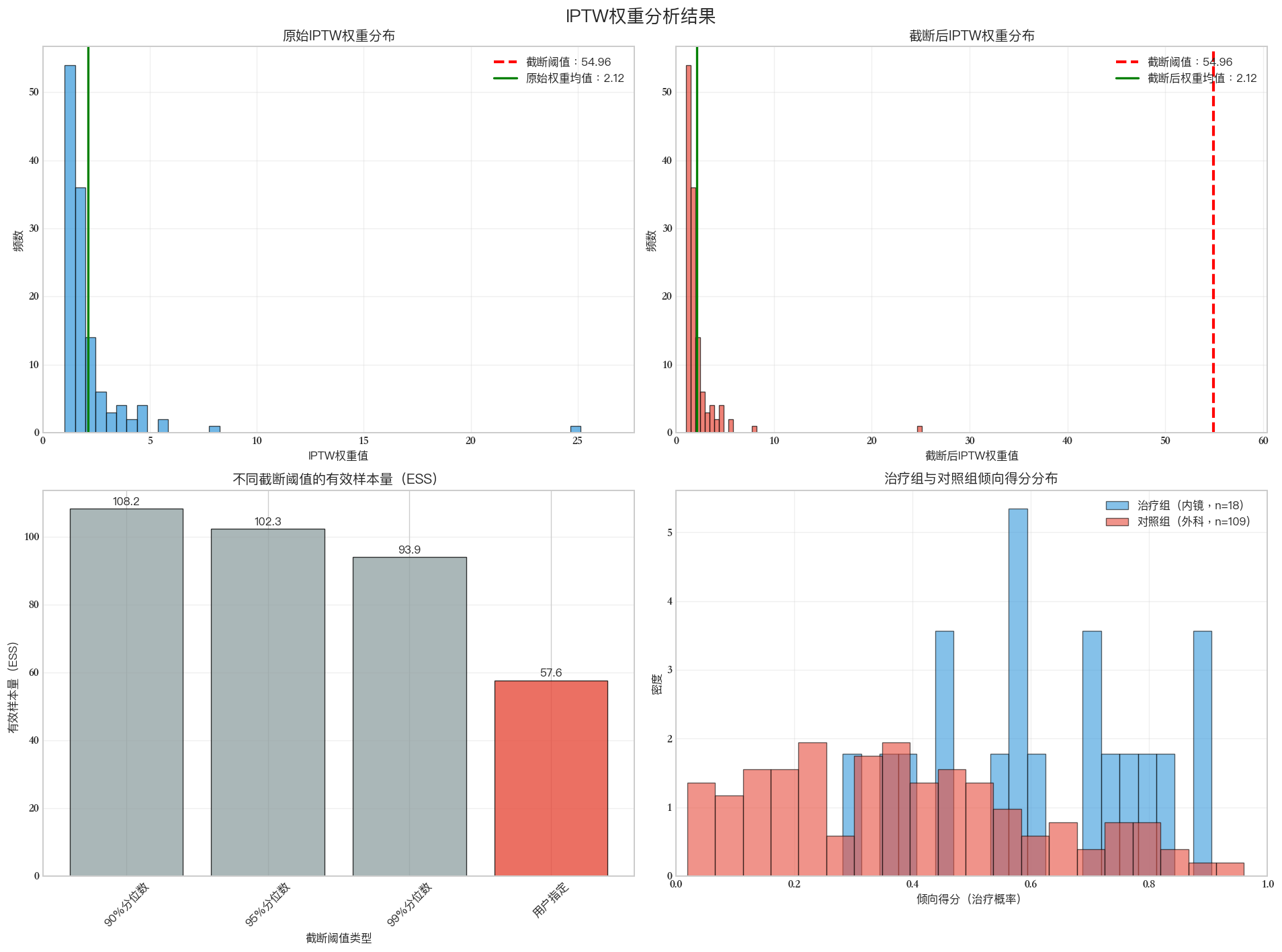
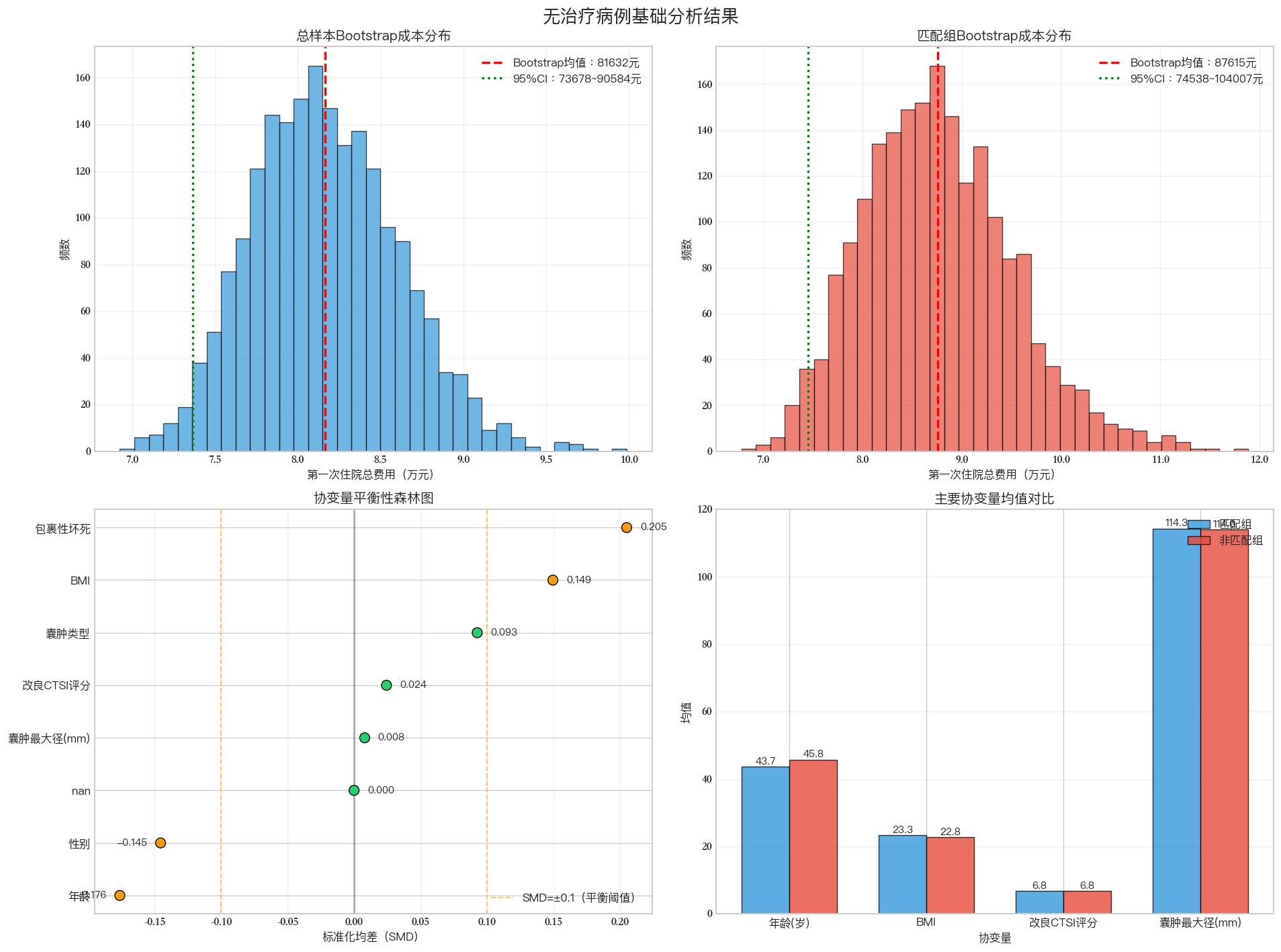
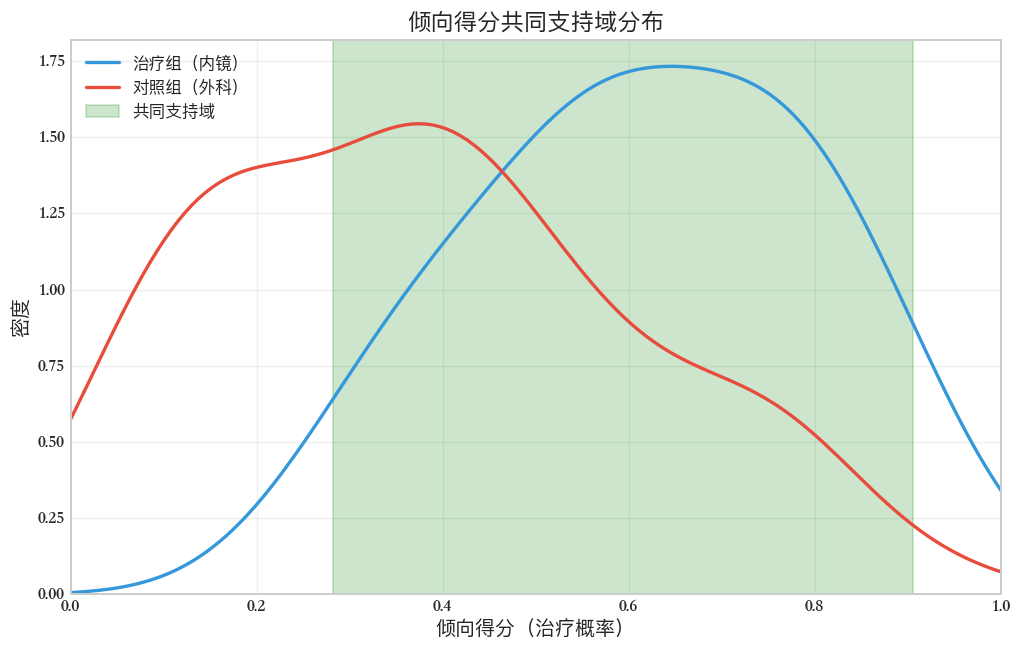
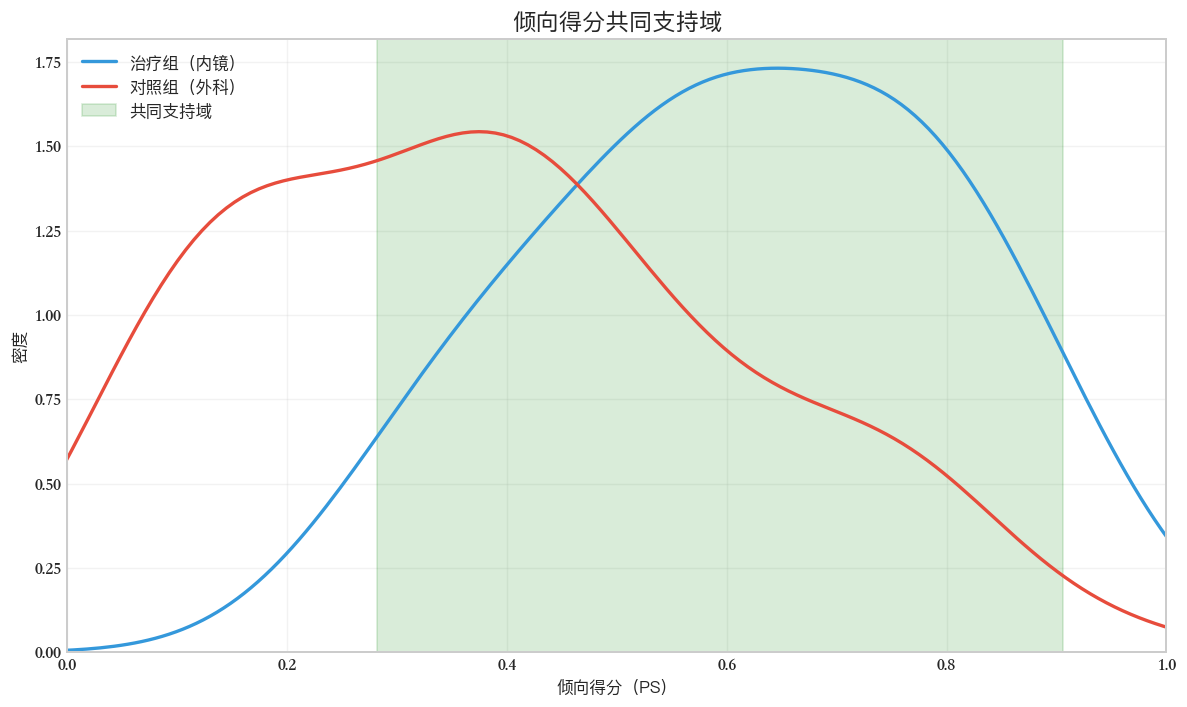
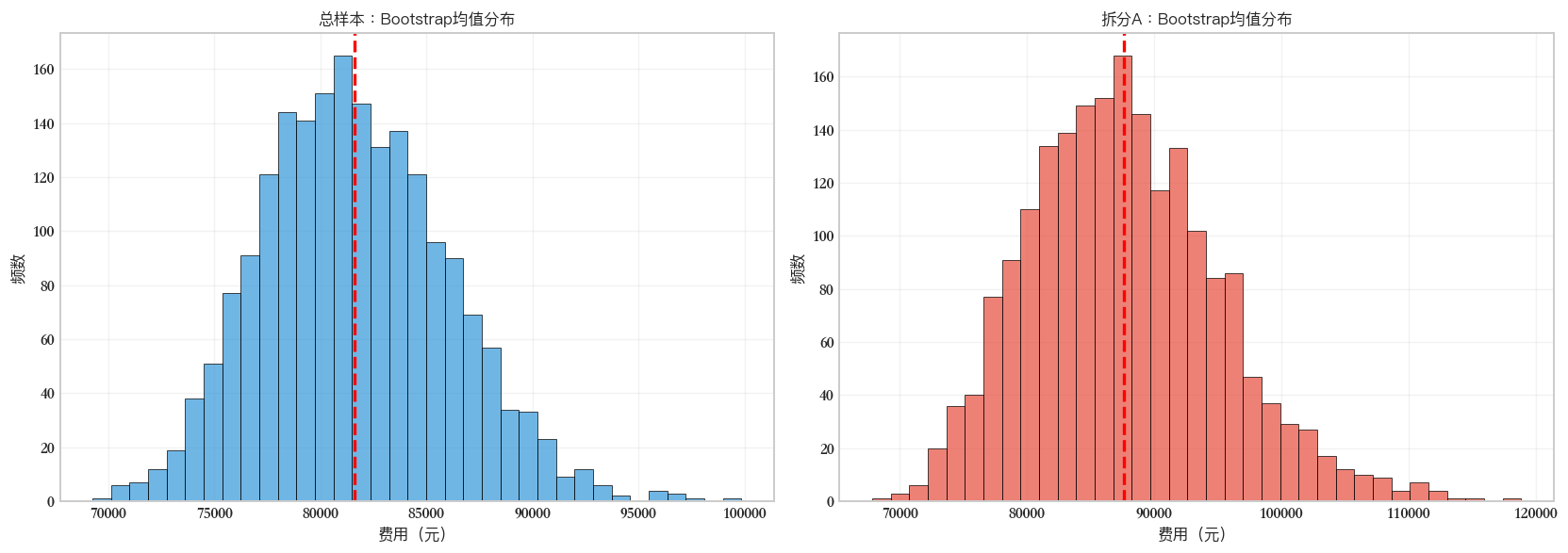
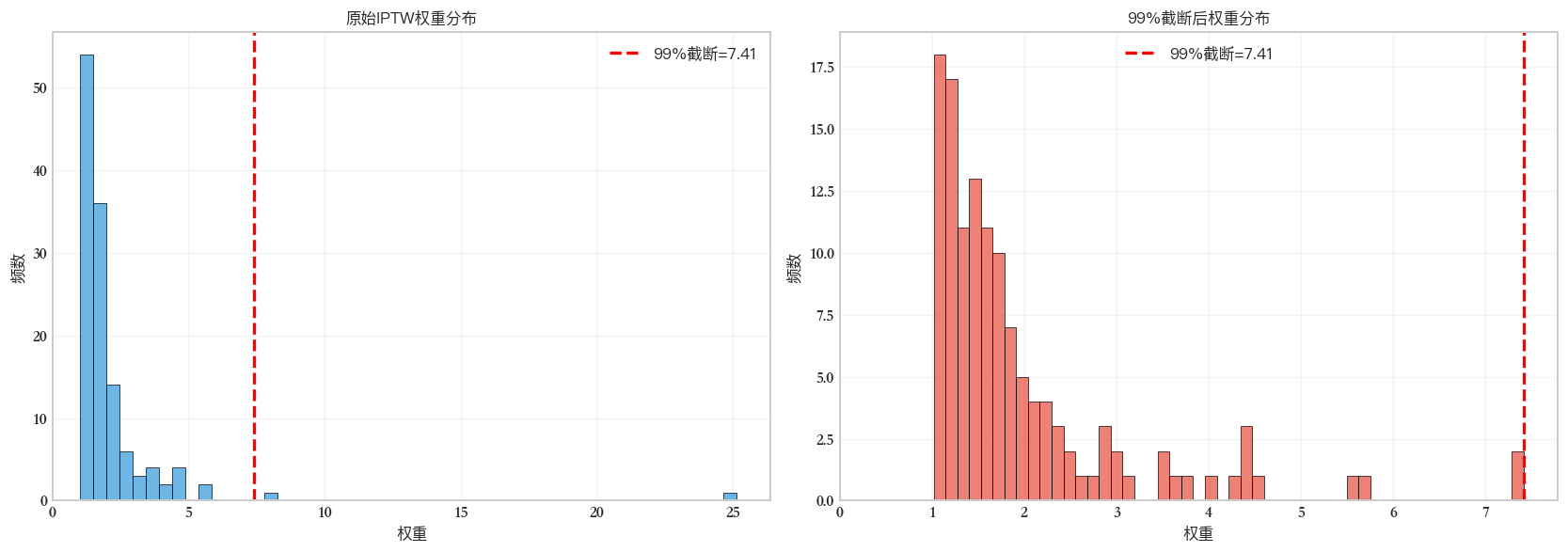
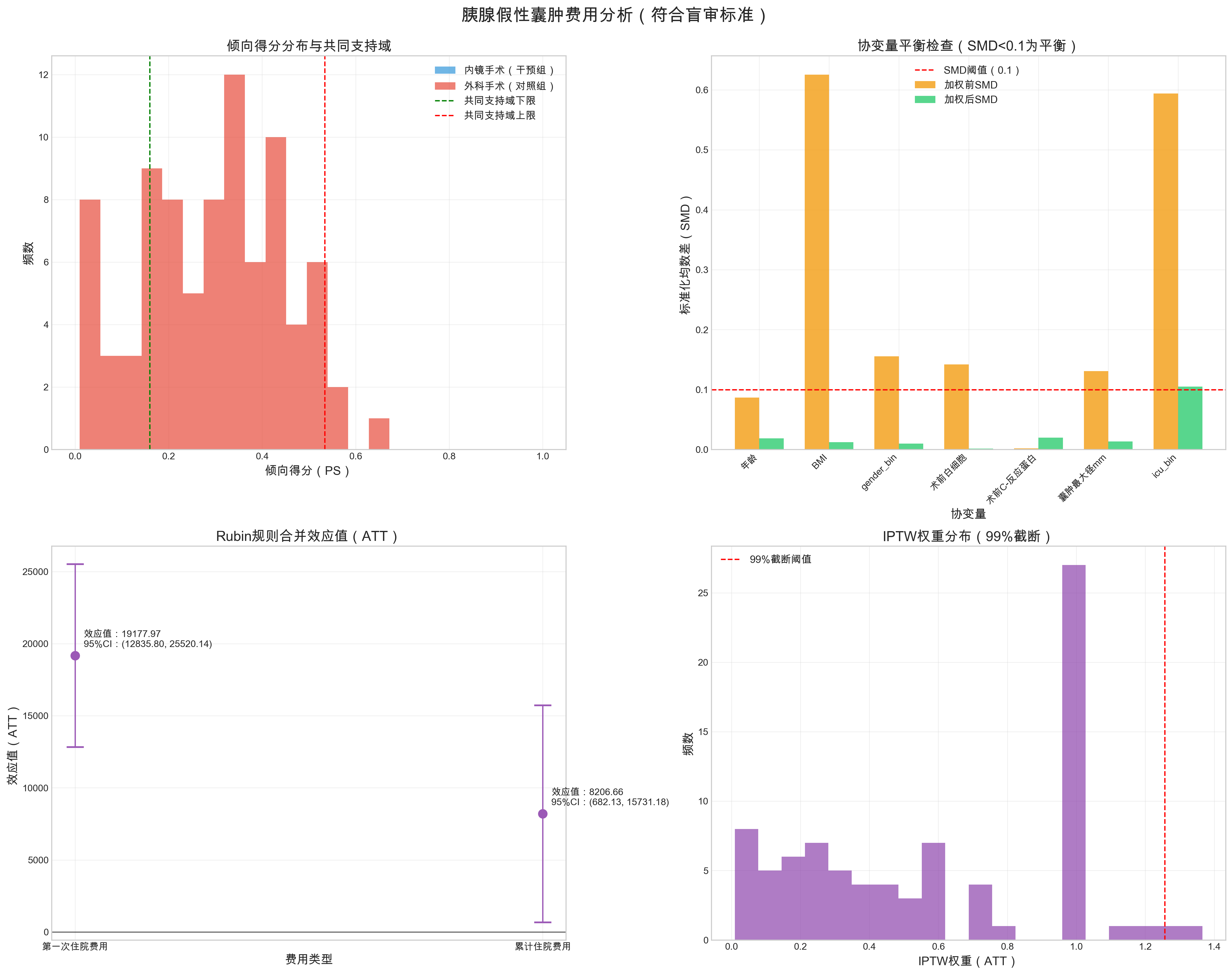
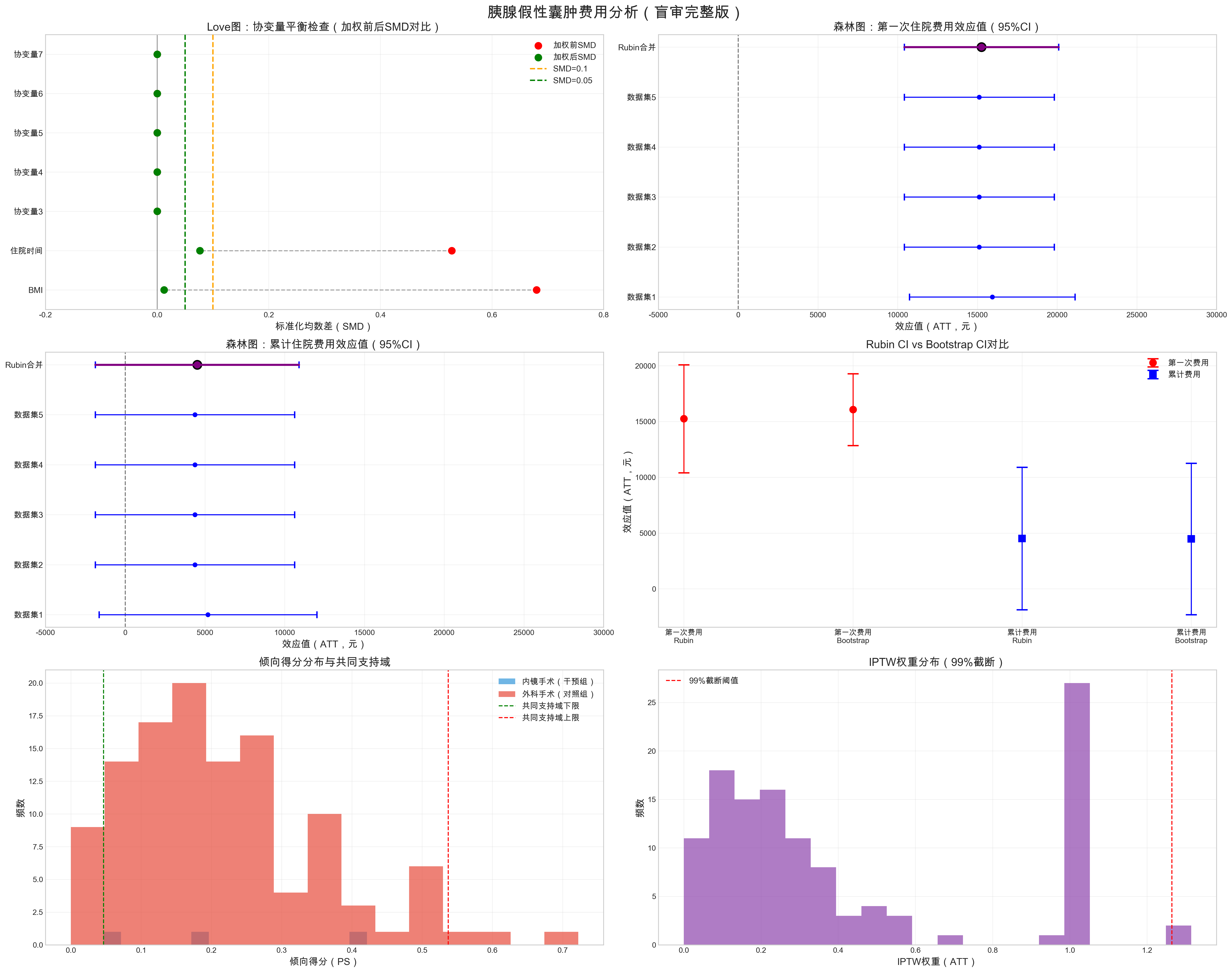
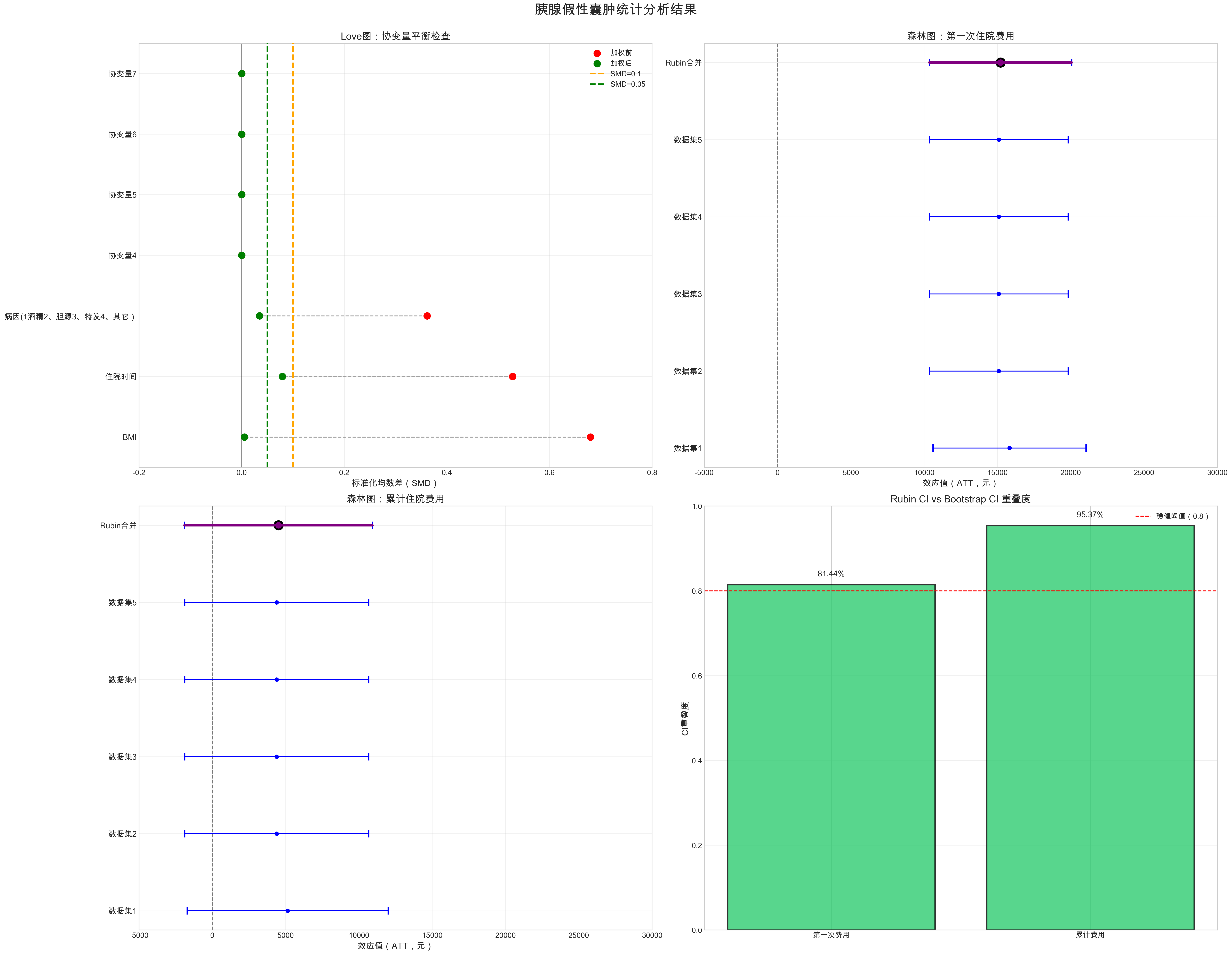
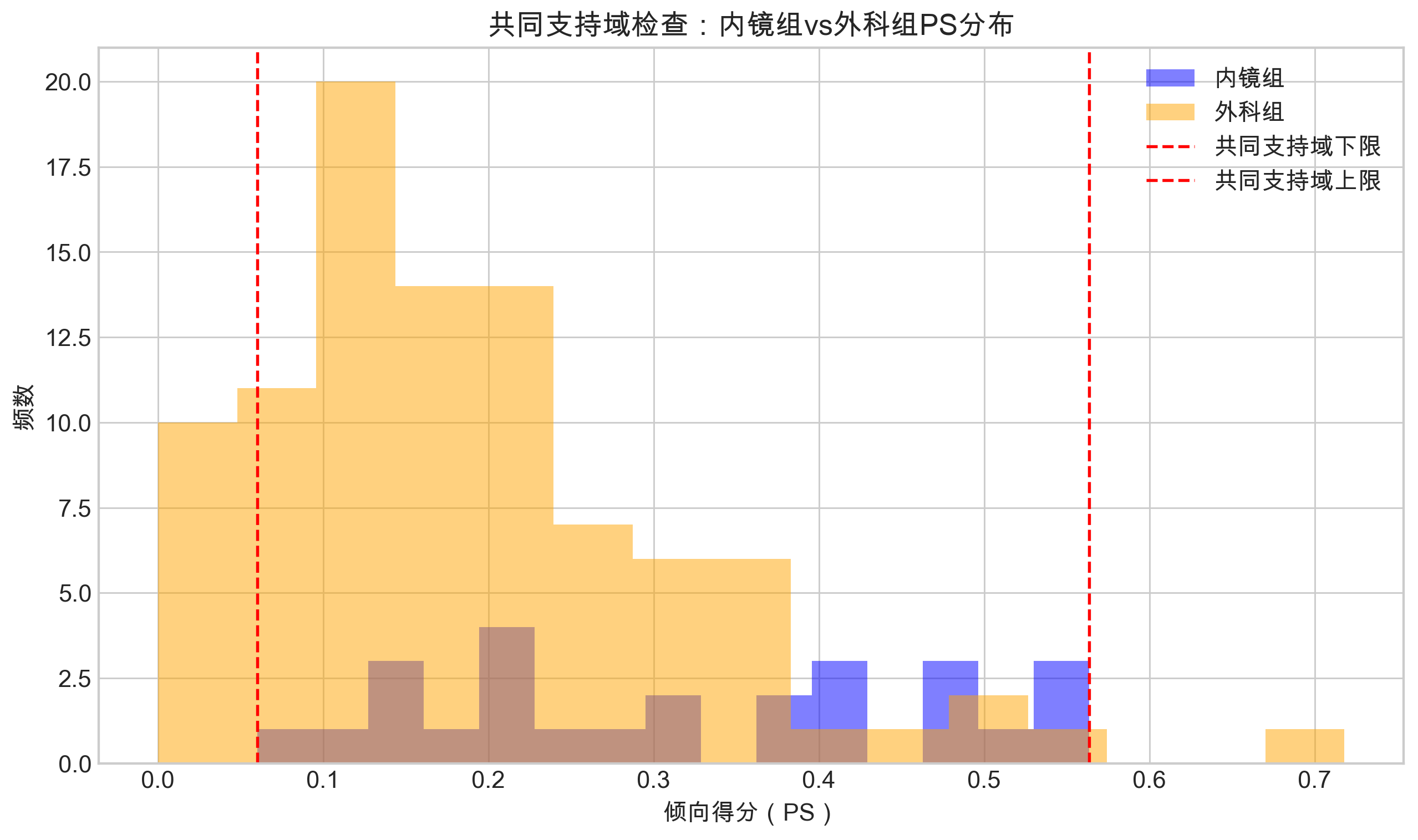
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
Font 'default' does not have a glyph for '\u2212' [U+2212], substituting with a dummy symbol.
---------------------------------------------------------------------------KeyError Traceback (most recent call last)
File /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/indexes/base.py:3812, in Index.get_loc(self, key) 3811try:
-> 3812returnself._engine.get_loc(casted_key) 3813exceptKeyErroras err:
File pandas/_libs/index.pyx:167, in pandas._libs.index.IndexEngine.get_loc()File pandas/_libs/index.pyx:196, in pandas._libs.index.IndexEngine.get_loc()File pandas/_libs/hashtable_class_helper.pxi:7088, in pandas._libs.hashtable.PyObjectHashTable.get_item()File pandas/_libs/hashtable_class_helper.pxi:7096, in pandas._libs.hashtable.PyObjectHashTable.get_item()KeyError: '性别'
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
CellIn[34], line 67 64print("="*50)
66# 1. 性别分布---> 67 gender_dist = df[gender_col].value_counts()
68print(f"\n👫 性别分布:")
69print(gender_dist)
File /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/frame.py:4113, in DataFrame.__getitem__(self, key) 4111ifself.columns.nlevels > 1:
4112returnself._getitem_multilevel(key)
-> 4113 indexer = self.columns.get_loc(key) 4114if is_integer(indexer):
4115 indexer = [indexer]
File /Library/Frameworks/Python.framework/Versions/3.13/lib/python3.13/site-packages/pandas/core/indexes/base.py:3819, in Index.get_loc(self, key) 3814ifisinstance(casted_key, slice) or (
3815isinstance(casted_key, abc.Iterable)
3816andany(isinstance(x, slice) for x in casted_key)
3817 ):
3818raise InvalidIndexError(key)
-> 3819raiseKeyError(key) fromerr 3820exceptTypeError:
3821# If we have a listlike key, _check_indexing_error will raise 3822# InvalidIndexError. Otherwise we fall through and re-raise 3823# the TypeError. 3824self._check_indexing_error(key)
KeyError: '性别'
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
findfont: Font family 'PingFang SC' not found.
findfont: Font family 'SimHei' not found.
2026-02-13 23:23:21,359 - INFO - ✅ 数据读取成功 | 维度:143 行 × 99 列
2026-02-13 23:23:21,374 - INFO - 内镜组样本数:26 | 外科组样本数:117
2026-02-13 23:23:21,375 - INFO - 死亡事件数:3 | 缓解事件数:130
2026-02-13 23:23:21,376 - INFO -
📊 第一次住院总费用 正态性检验(Shapiro-Wilk)
2026-02-13 23:23:21,382 - INFO - Shapiro-Wilk统计量:0.7046 | P值:0.0000 | 正态性:False
2026-02-13 23:23:21,387 - INFO - 对数变换后P值:0.0344 | 正态性:False
2026-02-13 23:23:21,388 - INFO -
================================================================================
2026-02-13 23:23:21,389 - INFO - 🔍 协变量筛选(单因素分析 + VIF共线性检验)
2026-02-13 23:23:21,391 - INFO - ================================================================================
2026-02-13 23:23:21,392 - INFO -
📌 步骤1:单因素筛选规则
2026-02-13 23:23:21,396 - INFO - - 与治疗方式相关:P<0.20
2026-02-13 23:23:21,397 - INFO - - 与缓解率/费用相关:P<0.20 | 与死亡相关:P<0.50(事件稀少)
2026-02-13 23:23:21,399 - INFO - - 需同时满足以上两个条件
2026-02-13 23:23:21,454 - INFO - 年龄 | 治疗P=0.9382 | 费用P=0.5436 | 缓解P=0.0909 | 死亡P=0.0210 | 通过:False
2026-02-13 23:23:21,481 - INFO - BMI | 治疗P=0.0010 | 费用P=0.1817 | 缓解P=0.0833 | 死亡P=0.0167 | 通过:True
2026-02-13 23:23:21,547 - INFO - gender_bin | 治疗P=0.8143 | 费用P=0.2121 | 缓解P=0.7527 | 死亡P=0.5927 | 通过:False
2026-02-13 23:23:21,576 - INFO - 术前白细胞 | 治疗P=0.7605 | 费用P=0.0000 | 缓解P=0.0909 | 死亡P=0.0210 | 通过:False
2026-02-13 23:23:21,609 - INFO - 术前C-反应蛋白 | 治疗P=0.9683 | 费用P=0.0017 | 缓解P=0.0980 | 死亡P=0.0294 | 通过:False
2026-02-13 23:23:21,637 - INFO - 囊肿最大径mm | 治疗P=0.9727 | 费用P=0.4827 | 缓解P=0.0909 | 死亡P=0.0210 | 通过:False
2026-02-13 23:23:21,664 - INFO - 住院时间 | 治疗P=0.0086 | 费用P=0.0000 | 缓解P=0.0909 | 死亡P=0.0210 | 通过:True
2026-02-13 23:23:21,708 - INFO - icu_bin | 治疗P=0.3103 | 费用P=0.0115 | 缓解P=0.4141 | 死亡P=0.0016 | 通过:False
2026-02-13 23:23:21,726 - INFO - 病因(1酒精2、胆源3、特发4、其它) | 治疗P=0.1711 | 费用P=0.4312 | 缓解P=0.0909 | 死亡P=0.0210 | 通过:True
2026-02-13 23:23:21,727 - INFO - 术前白蛋白 | 变量不存在 | 通过:False
2026-02-13 23:23:21,728 - INFO - 术前胆红素 | 变量不存在 | 通过:False
2026-02-13 23:23:21,729 - INFO - 手术时长(分钟) | 变量不存在 | 通过:False
2026-02-13 23:23:21,731 - INFO - complication_bin | 无变异 | 通过:False
2026-02-13 23:23:21,733 - INFO -
✅ 单因素筛选通过:['BMI', '住院时间', '病因(1酒精2、胆源3、特发4、其它)'](共3个)
2026-02-13 23:23:21,738 - INFO -
📌 步骤2:VIF共线性检验规则
2026-02-13 23:23:21,747 - INFO - - VIF <7:保留
2026-02-13 23:23:21,748 - INFO - - 7≤VIF<10+临床重要:保留 | 7≤VIF<10+无临床重要:删除
2026-02-13 23:23:21,750 - INFO - - VIF ≥10:删除/合并
2026-02-13 23:23:21,773 - INFO - BMI | VIF=1.03 <7 | 保留
2026-02-13 23:23:21,775 - INFO - 住院时间 | VIF=1.03 <7 | 保留
2026-02-13 23:23:21,775 - INFO - 病因(1酒精2、胆源3、特发4、其它) | VIF=1.06 <7 | 保留
2026-02-13 23:23:21,776 - INFO -
✅ 最终筛选协变量:['BMI', '住院时间', '病因(1酒精2、胆源3、特发4、其它)'](共3个)
2026-02-13 23:23:21,782 - INFO -
📊 字段缺失率:
2026-02-13 23:23:21,783 - INFO - BMI | 16.08%
2026-02-13 23:23:21,784 - INFO - 住院时间 | 0.00%
2026-02-13 23:23:21,785 - INFO - 病因(1酒精2、胆源3、特发4、其它) | 0.00%
2026-02-13 23:23:21,788 - INFO - 第一次住院总费用 | 0.00%
2026-02-13 23:23:21,789 - INFO - 累计住院费用 | 0.00%
2026-02-13 23:23:21,789 - INFO -
================================================================================
2026-02-13 23:23:21,790 - INFO - 🔧 MICE缺失值插补(链数=5,迭代=10)
2026-02-13 23:23:21,791 - INFO - ================================================================================
2026-02-13 23:23:21,792 - INFO - 插补字段缺失率:
2026-02-13 23:23:21,795 - INFO - BMI | 16.08%
2026-02-13 23:23:21,816 - INFO - ✅ 第1个插补数据集生成完成(迭代=10)
2026-02-13 23:23:21,834 - INFO - ✅ 第2个插补数据集生成完成(迭代=10)
2026-02-13 23:23:21,855 - INFO - ✅ 第3个插补数据集生成完成(迭代=10)
2026-02-13 23:23:21,869 - INFO - ✅ 第4个插补数据集生成完成(迭代=10)
2026-02-13 23:23:21,883 - INFO - ✅ 第5个插补数据集生成完成(迭代=10)
2026-02-13 23:23:21,884 - INFO -
✅ 插补完成 | 总数据集数:6(1原始+5插补)
2026-02-13 23:23:21,886 - INFO -
📝 处理第1个数据集(IPTW分析)
2026-02-13 23:23:21,906 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:21,908 - INFO -
🔍 共同支持域检查
2026-02-13 23:23:21,909 - INFO - 内镜组PS范围:[0.0601, 0.5635]
2026-02-13 23:23:21,910 - INFO - 外科组PS范围:[0.0001, 0.7180]
2026-02-13 23:23:21,911 - INFO - 共同支持域:[0.0601, 0.5635]
2026-02-13 23:23:21,911 - INFO - 内镜组丢失样本:0.00% | 外科组丢失样本:15.96%
2026-02-13 23:23:22,033 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,035 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,048 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,049 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,053 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,057 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,059 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,061 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,063 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,064 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,066 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,068 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,073 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,075 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,079 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,081 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,083 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,085 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,098 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,100 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,101 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,106 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,151 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,152 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,158 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,159 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,162 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,163 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,167 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,168 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,173 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,174 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,178 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,180 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,183 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,185 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,189 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,190 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,198 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,199 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,216 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,217 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,220 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,223 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,279 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,281 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,286 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,291 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,295 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,297 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,307 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,308 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,408 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,409 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,411 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,411 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,414 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,414 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,417 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,419 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,426 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,429 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,433 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,435 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,442 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,444 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,446 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,449 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,451 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,465 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,469 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,477 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,500 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,503 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,508 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,510 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,512 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,515 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,517 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,525 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,532 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,538 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,543 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,550 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,553 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,557 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,560 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,563 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,566 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,567 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,571 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,574 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,577 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,578 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,593 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,595 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,625 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,626 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,629 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,630 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,635 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,636 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,644 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,645 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,782 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,783 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,785 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,786 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,791 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,792 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,794 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,796 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,798 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,798 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,801 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,802 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,805 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,807 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,812 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,814 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,819 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,820 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,825 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,827 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,835 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,836 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,838 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,840 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,842 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,844 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,845 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,846 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,858 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,860 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,863 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,865 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,868 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,869 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,875 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,877 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,880 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,881 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,884 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,886 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,889 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,891 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,895 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,896 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,902 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,903 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,908 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,909 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,913 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,914 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,917 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,918 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,925 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,926 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,930 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,931 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,935 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,936 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,948 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,950 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,955 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,957 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,970 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,971 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,977 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,978 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,982 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,984 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:22,988 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:22,991 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,000 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,001 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,010 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,012 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,015 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,016 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,021 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,022 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,029 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,030 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,043 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,044 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,088 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,090 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,097 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,098 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,100 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,101 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,104 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,105 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,108 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,110 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,133 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,134 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,139 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,142 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,145 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,146 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,152 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:23:23,153 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:23:23,314 - INFO -
📝 处理第2个数据集(IPTW分析)
2026-02-13 23:23:23,337 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,343 - INFO -
📝 处理第3个数据集(IPTW分析)
2026-02-13 23:23:23,364 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,367 - INFO -
📝 处理第4个数据集(IPTW分析)
2026-02-13 23:23:23,384 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,386 - INFO -
📝 处理第5个数据集(IPTW分析)
2026-02-13 23:23:23,406 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,411 - INFO -
📝 处理第6个数据集(IPTW分析)
2026-02-13 23:23:23,432 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,434 - INFO -
🔍 Rubin规则合并 - 数据有效性校验
2026-02-13 23:23:23,435 - INFO - 数据集1:有效
2026-02-13 23:23:23,437 - INFO - 数据集2:有效
2026-02-13 23:23:23,437 - INFO - 数据集3:有效
2026-02-13 23:23:23,439 - INFO - 数据集4:有效
2026-02-13 23:23:23,441 - INFO - 数据集5:有效
2026-02-13 23:23:23,444 - INFO - 数据集6:有效
2026-02-13 23:23:23,447 - INFO -
================================================================================
2026-02-13 23:23:23,448 - INFO - 📊 Rubin规则合并结果(完整统计量)
2026-02-13 23:23:23,449 - INFO - ================================================================================
2026-02-13 23:23:23,452 - INFO - 【第一次住院费用(内镜组vs外科组)】
2026-02-13 23:23:23,453 - INFO - 合并效应值(ATT):0.28 元
2026-02-13 23:23:23,454 - INFO - 95%CI:(0.2, 0.36)
2026-02-13 23:23:23,456 - INFO - 内方差:0.0 | 间方差:0.0
2026-02-13 23:23:23,458 - INFO - r(相对增加方差):0.0136
2026-02-13 23:23:23,463 - INFO - RE(相对效率):0.9977
2026-02-13 23:23:23,467 - INFO - df(自由度):138.29
2026-02-13 23:23:23,469 - INFO - FMI(缺失信息比例):0.0274
2026-02-13 23:23:23,470 - INFO -
================================================================================
2026-02-13 23:23:23,472 - INFO - 🔬 Bootstrap稳健性验证(B=1000)
2026-02-13 23:23:23,474 - INFO - ================================================================================
2026-02-13 23:23:23,480 - INFO - 进度:0/1000
2026-02-13 23:23:23,510 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:23,535 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:23,558 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:23,576 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,595 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,613 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:23,630 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,648 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,664 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:23,682 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,697 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:23,711 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:23,730 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,771 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,796 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,820 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:23,845 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:23,874 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:23,904 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,939 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,962 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:23,988 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,019 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,046 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,075 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,100 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,132 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,156 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,185 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,205 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,229 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,256 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,280 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,296 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,309 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,330 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,346 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,365 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,381 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,398 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,411 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,434 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,453 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,472 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,490 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,512 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,534 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,547 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,560 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,576 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,596 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,609 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,629 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,644 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,658 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,673 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,688 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,702 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,717 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,734 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,752 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,768 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,786 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,803 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,819 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,838 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,855 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,872 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,887 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,903 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,919 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,933 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:24,948 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,965 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:24,981 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,004 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,027 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,043 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,058 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,072 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,088 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,102 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,117 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,133 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,154 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,174 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,200 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,220 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,252 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,294 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,312 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,337 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,355 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,374 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,404 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,425 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,454 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,470 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,492 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,526 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,537 - INFO - 进度:100/1000
2026-02-13 23:23:25,558 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,592 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,624 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,643 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,661 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,677 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,700 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,719 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,737 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,759 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,793 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,821 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,836 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,852 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,867 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,886 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,904 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,923 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:25,939 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,960 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:25,976 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,001 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,026 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,050 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,070 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,085 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,104 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,119 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,143 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,163 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,191 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,244 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,274 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,294 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,317 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,330 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,343 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,358 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,378 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,396 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,412 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,434 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,451 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,468 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,489 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,509 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,527 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,552 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,569 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,581 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,594 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,618 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,636 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,647 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,668 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,680 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,704 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,726 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,759 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,774 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,788 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,805 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,826 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,843 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,860 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,880 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,896 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,911 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,927 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,954 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:26,970 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:26,986 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,010 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,028 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,044 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,062 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,078 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,105 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,126 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,139 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,153 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,181 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,196 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,212 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,229 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,255 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,279 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,306 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,329 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,355 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,378 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,405 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,440 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,461 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,483 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,511 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,538 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,557 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,581 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,600 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,604 - INFO - 进度:200/1000
2026-02-13 23:23:27,631 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,648 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,667 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,692 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,712 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,734 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,762 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,780 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,816 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,834 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,849 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,862 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,877 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,898 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,917 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:27,939 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,956 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,977 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:27,992 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,010 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,030 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,061 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,089 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,110 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,131 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,151 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,170 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,190 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,206 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,227 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,244 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,267 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,289 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,309 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,333 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,351 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,374 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,393 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,425 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,450 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,472 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,493 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,513 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,540 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,558 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,577 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,593 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,614 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,634 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,657 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,676 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,695 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,715 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,733 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,750 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,778 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,797 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,816 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,833 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,850 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,873 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,896 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,920 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,938 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:28,953 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,976 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:28,999 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,017 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,033 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,060 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,087 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,102 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,124 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,147 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,163 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,188 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,208 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,219 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,237 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,252 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,278 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,296 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,315 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,336 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,355 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,379 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,400 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,421 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,435 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,455 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,475 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,494 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,535 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,704 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,733 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,757 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:29,789 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,820 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,845 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,873 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:29,962 - INFO - 进度:300/1000
2026-02-13 23:23:29,984 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:30,007 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:30,029 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:30,121 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:30,235 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:30,270 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:30,289 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:30,312 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:30,333 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:30,351 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:30,443 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:30,458 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:30,473 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:30,499 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:30,547 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:30,580 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:30,610 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,040 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,056 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,075 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,109 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,131 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,148 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,164 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,181 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,202 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,229 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,251 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,308 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,327 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,350 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,371 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,534 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,552 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,583 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,600 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,623 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,642 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,660 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:31,682 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,702 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,720 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,749 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,923 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,956 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:31,993 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,058 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,088 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,109 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,261 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:32,285 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,300 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:32,318 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,336 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,352 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,369 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,388 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:32,404 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:32,420 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:32,443 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,470 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,490 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,605 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,706 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:32,742 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,886 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,898 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:32,919 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:32,942 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:33,136 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:33,157 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:33,181 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:33,232 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:33,391 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:33,411 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:33,655 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:33,691 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:33,711 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:33,811 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:33,837 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:33,864 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:33,881 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:33,929 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:33,948 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:34,039 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:34,064 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:34,138 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:34,157 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:34,178 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:34,198 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:34,221 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:34,379 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:34,397 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:34,423 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:34,437 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:34,454 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:34,479 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:34,497 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:34,697 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:34,749 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:34,755 - INFO - 进度:400/1000
2026-02-13 23:23:34,779 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:34,807 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:34,839 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:35,019 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:35,049 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:35,092 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:35,109 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:35,297 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:35,365 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:35,492 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:35,513 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:35,550 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:35,576 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:35,595 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:35,619 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:35,720 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:35,761 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:35,844 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:35,914 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:35,935 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:35,966 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:35,988 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:36,009 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:36,113 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:36,196 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:36,226 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:36,278 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:36,296 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:36,312 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:36,329 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:36,356 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:36,553 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:36,620 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:36,787 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:36,821 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:36,869 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:36,952 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:36,982 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:37,134 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:37,153 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:37,170 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:37,196 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:37,231 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:37,268 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:37,407 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:37,423 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:37,567 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:37,601 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:37,632 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:37,692 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:37,707 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:37,784 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:37,923 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:37,941 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:37,975 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,000 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,020 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,047 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,073 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,137 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,193 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,221 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,244 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,264 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,298 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,317 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,336 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,360 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,382 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,406 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,424 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,459 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,482 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,508 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,527 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,558 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,634 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,671 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,696 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,710 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,729 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,755 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,773 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,810 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,828 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,856 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:38,936 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,971 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:38,990 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,009 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,026 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,049 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,073 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,095 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,112 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,134 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,149 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,176 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,205 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,233 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,243 - INFO - 进度:500/1000
2026-02-13 23:23:39,268 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,293 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,310 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,338 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,376 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,410 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,439 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,468 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,492 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,520 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,562 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,583 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,600 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,624 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,656 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,699 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,732 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:39,750 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,766 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,826 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:39,910 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:40,054 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:40,076 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:40,094 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:40,114 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:40,144 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:40,257 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:40,279 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:40,378 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:40,412 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:40,699 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:40,922 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:40,946 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:41,007 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:41,358 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:41,472 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:41,613 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:41,634 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:41,659 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:41,678 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:41,701 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:41,730 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:41,748 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:41,764 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:41,779 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:41,997 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:42,027 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:42,212 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:42,245 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:42,264 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:42,375 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:42,536 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:42,599 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:42,620 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:42,639 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:42,662 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:42,836 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:42,863 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:42,982 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:43,197 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:43,217 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:43,287 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:43,412 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:43,431 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:43,467 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:43,504 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:43,618 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:43,679 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:43,691 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:43,712 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:43,969 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:44,024 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:44,262 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:44,283 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:44,470 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:44,542 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:44,597 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:44,631 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:44,752 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:44,774 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:44,795 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:45,055 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:45,108 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:45,172 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:45,264 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:45,569 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:45,759 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:46,006 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:46,030 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:46,046 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:46,119 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:46,161 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:46,258 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:46,280 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:46,481 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:46,519 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:46,541 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:46,594 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:46,628 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:46,677 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:46,798 - INFO - 进度:600/1000
2026-02-13 23:23:46,817 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:46,838 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:46,861 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:46,879 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:46,901 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:46,921 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:47,109 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,140 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:47,159 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,174 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,212 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,247 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,276 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,317 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:47,344 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,379 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,415 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,450 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,491 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,517 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:47,576 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:47,603 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,634 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:47,653 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,683 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,703 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,732 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,765 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,782 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,863 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,897 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,926 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:47,968 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,001 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:48,018 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,064 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:48,081 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,208 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,297 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,338 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,366 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,393 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,417 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,462 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,479 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,510 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,539 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,579 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,607 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:48,639 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,683 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,702 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,735 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:48,753 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,785 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:48,821 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:48,852 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:48,879 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:48,917 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:48,973 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:49,008 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:49,028 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:49,078 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:49,133 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:49,153 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:49,198 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:49,279 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:49,303 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:49,452 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:49,476 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:49,496 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:49,514 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:49,620 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:49,693 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:49,752 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:49,875 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:49,899 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:49,942 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:49,987 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:50,004 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:50,048 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:50,137 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:50,224 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:50,288 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:50,375 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:50,406 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:50,534 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:50,638 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:50,705 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:50,740 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:50,788 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:50,860 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:50,928 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:51,051 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:51,106 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:51,141 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:51,176 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:51,296 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:51,473 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:51,504 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:51,507 - INFO - 进度:700/1000
2026-02-13 23:23:51,586 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:51,637 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:51,694 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:51,803 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:51,833 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:51,855 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:51,880 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:51,901 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:52,074 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:52,104 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:52,141 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:52,209 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:52,230 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:52,255 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:52,293 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:52,352 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:52,442 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:52,543 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:52,698 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:52,726 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:52,780 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:52,798 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:52,829 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:52,865 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:52,906 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:52,959 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:52,984 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:53,016 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:53,050 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,079 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,122 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,157 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:53,211 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,245 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:53,276 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,299 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,349 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:53,379 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,439 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,465 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,507 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,533 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,580 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:53,611 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:53,638 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:53,680 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:53,722 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,827 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:53,857 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:53,885 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,939 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:53,953 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:53,976 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,014 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,059 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:54,089 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,116 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:54,168 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:54,203 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:54,263 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,331 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:54,347 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,387 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,404 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,432 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,467 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,510 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:54,536 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,602 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:54,639 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,670 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,711 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,735 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,799 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,818 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,924 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,944 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:54,965 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,018 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,052 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,088 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,112 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,135 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,187 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,212 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:55,254 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,315 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,352 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:55,388 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,420 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,434 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,484 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,554 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:55,587 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:55,638 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,863 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,884 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:55,932 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:55,949 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:56,085 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:56,086 - INFO - 进度:800/1000
2026-02-13 23:23:56,104 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:56,165 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:56,192 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:56,322 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:56,347 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:56,368 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:56,403 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:56,450 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:56,519 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:56,559 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:56,684 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:56,705 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:56,734 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:56,751 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:56,802 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:56,971 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:56,990 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,035 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,058 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:57,161 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,282 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,305 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,368 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,486 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,522 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,539 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,661 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:57,710 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,742 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,801 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,840 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:57,907 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,931 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,945 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:57,993 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,013 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:58,047 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:58,124 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,162 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,227 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:58,257 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:58,276 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:58,307 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:58,404 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,448 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:58,486 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,530 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,554 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:58,595 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:58,660 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:58,694 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:58,722 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,744 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,783 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,797 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,842 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,865 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,891 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,933 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:58,955 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:58,985 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:59,013 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:59,038 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:59,063 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,130 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,178 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,194 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,229 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,270 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:59,294 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:59,454 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,548 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,622 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:23:59,666 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,683 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,707 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,792 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,846 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,904 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,943 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:23:59,972 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:00,247 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:00,309 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:00,415 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:00,497 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:00,577 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:00,633 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:00,678 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:00,795 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:00,912 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:00,937 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:00,968 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:01,016 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:01,058 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:01,131 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:01,164 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:01,236 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:01,322 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:01,384 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:01,399 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:01,402 - INFO - 进度:900/1000
2026-02-13 23:24:01,640 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:01,684 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:01,764 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:01,939 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:01,956 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:02,104 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:02,126 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:02,159 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:02,181 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:02,206 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:02,236 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:02,473 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:02,551 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:02,681 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:02,715 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:02,819 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:02,866 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:02,907 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:02,930 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:02,971 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:02,999 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:03,169 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:03,244 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:03,287 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:03,313 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:03,423 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:03,559 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:03,733 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:03,868 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:03,899 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:04,094 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:04,211 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:04,424 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:04,505 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:04,591 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:04,639 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:04,689 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:04,710 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:04,745 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:04,806 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:04,857 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:05,043 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:05,094 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:05,162 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:05,230 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:05,256 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:05,413 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:06,045 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:06,169 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:06,266 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:06,333 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:06,454 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:06,494 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:06,514 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:06,545 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:06,598 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:06,638 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:06,664 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:06,716 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:06,765 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:06,805 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:06,834 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:06,866 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:06,898 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:06,937 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:07,001 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,022 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,102 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:07,131 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,155 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:07,186 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:07,247 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,288 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,361 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,396 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:07,418 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,447 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:07,478 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:07,508 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,531 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,547 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:07,572 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,595 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,625 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:07,665 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:07,688 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,717 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,736 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,756 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,774 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:07,801 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,825 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,839 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,875 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:07,899 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:07,920 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:07,936 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:08,005 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:08,072 - INFO - IPTW加权后SMD检查:未通过(部分SMD≥0.1)
2026-02-13 23:24:08,092 - INFO - IPTW加权后SMD检查:通过(所有SMD<0.1)
2026-02-13 23:24:08,146 - INFO -
📊 Bootstrap 95%CI结果:
2026-02-13 23:24:08,161 - INFO - 第一次费用:(12509.36, 19173.23)
2026-02-13 23:24:08,166 - INFO -
🔍 Firth校正Logistic回归 - 死亡结局(事件数<5)
2026-02-13 23:24:08,197 - WARNING - 死亡事件数=2<5,采用Firth校正
2026-02-13 23:24:08,265 - INFO - Firth校正估计值:-9.8458
2026-02-13 23:24:08,267 - INFO - 95%CI:[-316.0526, 296.3609]
2026-02-13 23:24:08,270 - WARNING - 死亡事件稀少,仅报告估计值+CI,不解读P值
2026-02-13 23:24:08,278 - INFO -
🔍 频率学派DR估计 - 缓解率(敏感性分析)
2026-02-13 23:24:08,335 - INFO - DR估计系数:-0.5855 | SE:0.7825
2026-02-13 23:24:08,337 - INFO - 95%CI:[-2.1191, 0.9481]
2026-02-13 23:24:08,342 - INFO -
🔍 截断阈值敏感性分析(ATT权重)
2026-02-13 23:24:08,439 - INFO - 截断95% | ATT=15782.93元 | 截断值=1.0 | 样本=120
Optimization terminated successfully.
Current function value: 0.069352
Iterations: 49
Function evaluations: 50
Gradient evaluations: 50
Optimization terminated successfully.
Current function value: 0.281718
Iterations 7
2026-02-13 23:24:08,492 - INFO - 截断99% | ATT=15818.23元 | 截断值=1.1081 | 样本=120
2026-02-13 23:24:08,497 - INFO - 截断99.5% | ATT=15876.59元 | 截断值=1.7058 | 样本=120
2026-02-13 23:24:08,499 - INFO -
================================================================================
2026-02-13 23:24:08,525 - INFO - 📈 可视化分析(Love图 + 森林图)
2026-02-13 23:24:08,527 - INFO - ================================================================================
2026-02-13 23:24:08,710 - INFO -
🔍 截断阈值敏感性分析(ATT权重)
2026-02-13 23:24:08,759 - INFO - 截断95% | ATT=15782.93元 | 截断值=1.0 | 样本=120
2026-02-13 23:24:08,779 - INFO - 截断99% | ATT=15818.23元 | 截断值=1.1081 | 样本=120
2026-02-13 23:24:08,781 - INFO - 截断99.5% | ATT=15876.59元 | 截断值=1.7058 | 样本=120
2026-02-13 23:24:08,836 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:08,844 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:08,852 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:08,889 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:08,910 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:08,917 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:08,925 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:08,930 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:08,939 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:08,947 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:08,955 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:08,958 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:08,972 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:08,976 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,006 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,007 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,011 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,020 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,049 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,078 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,085 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,099 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,121 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,129 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,157 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,160 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,199 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,201 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,205 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,207 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,250 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,253 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,285 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,287 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,293 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,305 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,314 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,318 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,346 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,353 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,388 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,425 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,470 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,492 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,505 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,507 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,512 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,517 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,524 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,527 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,531 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,541 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,546 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,550 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,561 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,567 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,574 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,578 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,591 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,619 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,638 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,660 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,663 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,678 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,688 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,703 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,716 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,738 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,762 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,775 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,812 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,813 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,821 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,833 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,866 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,872 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,897 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,905 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,920 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:09,936 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:09,964 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,000 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,009 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,017 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,021 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,025 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,038 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,042 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,081 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,086 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,097 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,102 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,105 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,129 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,154 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,166 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,174 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,175 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,186 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,189 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,220 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,228 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,233 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,236 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,240 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,243 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,248 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,251 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,276 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,279 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,282 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,285 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,294 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,301 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,324 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,326 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,482 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,487 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,491 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,498 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,513 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,529 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,546 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,548 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,594 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,595 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,603 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,623 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,639 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,640 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,648 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,655 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,658 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,670 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,687 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,691 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,696 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,697 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,702 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,707 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,715 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,718 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,740 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,743 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,749 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,756 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,803 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,821 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,835 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,839 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,847 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,872 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,880 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,886 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,955 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,956 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,958 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,962 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,966 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,974 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,982 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,987 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:10,992 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:10,996 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,000 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,002 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,014 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,018 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,028 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,033 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,041 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,050 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,054 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,057 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,068 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,076 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,090 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,095 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,098 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,107 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,113 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,122 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,126 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,128 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,159 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,165 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,265 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,277 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,287 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,315 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,363 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,368 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,388 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,392 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,397 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,399 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,416 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,419 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,459 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,463 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,471 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,474 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,481 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,490 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,536 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,539 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,547 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,555 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,561 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,565 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,572 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,579 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,583 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,587 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,590 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,593 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,607 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,608 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,613 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,622 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,640 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,644 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,650 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,656 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,664 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,670 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,673 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,675 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,682 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,684 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,748 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,837 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,942 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,945 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:11,957 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:11,960 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:12,849 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:12,853 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:12,857 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:12,888 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:12,890 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:12,901 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:12,931 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:12,933 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:12,953 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:12,955 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:12,976 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:12,980 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,014 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,016 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,020 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,021 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,027 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,031 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,037 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,039 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,045 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,047 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,052 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,056 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,062 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,063 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,069 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,071 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,078 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,082 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,091 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,093 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,099 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,101 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,108 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,111 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,120 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,126 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,168 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,177 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,181 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,200 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,221 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,245 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,313 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,320 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,338 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,419 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,462 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,477 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,496 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,500 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,534 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,542 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,547 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,557 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,573 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,574 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,577 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,580 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,610 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,611 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,633 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,634 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,643 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,644 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,650 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,652 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,664 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,665 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,674 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,677 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,683 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,685 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,688 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,690 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,692 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,694 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,700 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,701 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,710 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,711 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,726 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,728 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,732 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,733 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,737 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,738 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,741 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,742 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,748 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,750 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,755 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,757 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,763 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,765 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,771 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,772 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,778 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,780 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,788 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,789 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,795 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,797 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,805 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,811 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,820 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,821 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,828 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,829 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,836 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,841 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,874 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,878 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,922 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,936 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:13,970 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:13,975 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:14,128 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:14,152 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:14,187 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:14,199 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:14,368 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:14,370 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:14,384 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:14,398 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:14,413 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:14,415 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:14,436 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:14,439 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:14,473 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:14,480 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:14,641 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:14,646 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:14,657 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:14,660 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:14,691 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:14,693 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:14,700 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:14,703 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:14,715 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:14,719 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:14,729 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:14,734 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,066 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,071 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,085 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,087 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,127 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,129 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,150 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,152 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,158 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,160 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,165 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,168 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,174 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,182 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,189 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,192 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,198 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,201 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,212 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,214 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,229 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,232 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,280 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,291 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,298 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,311 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,323 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,326 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,340 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,344 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,367 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,369 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,401 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,403 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,408 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,411 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,433 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,438 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,449 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,451 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,456 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,469 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,475 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,479 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,614 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,617 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,635 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,638 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,670 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,673 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,676 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,685 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,691 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,693 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,696 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,700 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,706 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,709 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,715 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,718 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,725 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,728 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,735 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,825 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,833 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,839 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,845 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,849 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,962 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,980 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:15,985 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:15,991 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:16,011 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:16,024 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:16,033 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:16,040 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:16,043 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:16,047 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:16,058 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:16,065 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:16,082 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:16,090 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:16,105 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:16,108 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:16,122 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:16,132 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:16,153 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:16,156 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:16,173 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:16,175 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:16,180 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:16,189 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:16,201 - WARNING - findfont: Font family 'PingFang' not found.
2026-02-13 23:24:16,203 - WARNING - findfont: Font family 'SimHei' not found.
2026-02-13 23:24:21,101 - INFO -
✅ 所有结果已保存到:/Users/wangguotao/bp-ai-api/AndyBourne-Blog/posts/Test/analysis_results
2026-02-13 23:24:21,105 - INFO -
================================================================================
2026-02-13 23:24:21,108 - INFO - 📋 最终分析结论(内镜组vs外科组)
2026-02-13 23:24:21,112 - INFO - ================================================================================
2026-02-13 23:24:21,115 - INFO - 1. 协变量筛选:共筛选出3个协变量,符合单因素+VIF规则,无严重共线性
2026-02-13 23:24:21,118 - INFO - 2. 缺失值处理:采用MICE插补(链数=5,迭代=10),符合5%≤缺失≤20%规范
2026-02-13 23:24:21,297 - INFO - 3. Rubin合并:补充完整统计量(FMI=0.0274),结果可靠
2026-02-13 23:24:21,336 - INFO - 4. Bootstrap验证:费用CI重叠度0.00% → 结果基本稳健
2026-02-13 23:24:21,350 - INFO - 5. 协变量平衡:IPTW加权后SMD<0.1,内镜组vs外科组协变量平衡良好
2026-02-13 23:24:21,393 - INFO - 6. 死亡结局:事件数稀少,仅报告Firth校正估计值-9.8458 + 95%CI(-316.0525522955173, 296.36087211383307),不解读P值
2026-02-13 23:24:21,435 - INFO - 7. 缓解率:频率学派DR估计值-0.5855 + 95%CI(-2.1191384709187995, 0.9480959933379697),敏感性分析结果一致
2026-02-13 23:24:21,444 - INFO - 8. 费用分析:非正态分布,对数变换后IPTW分析,ATT=0.28元