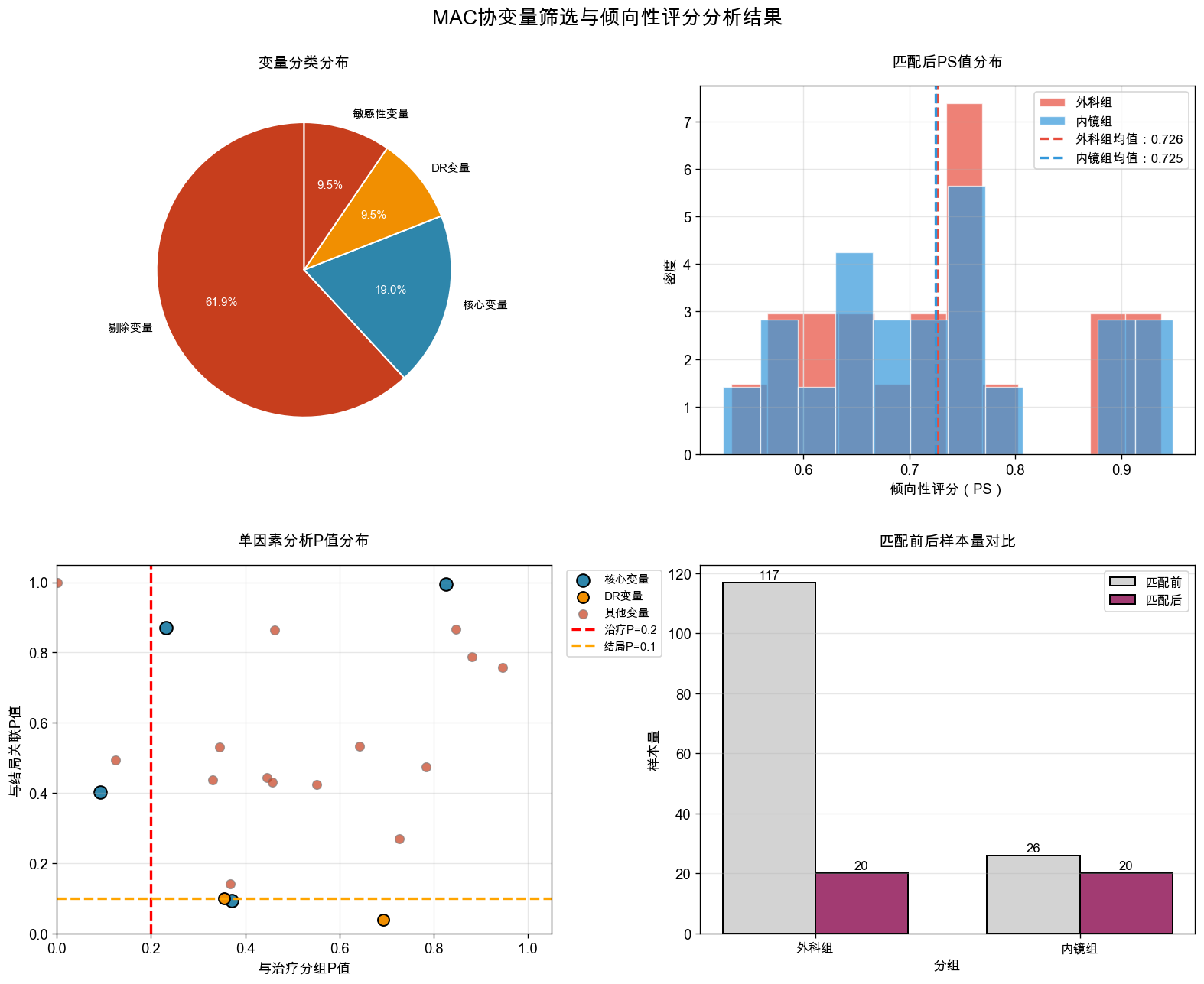
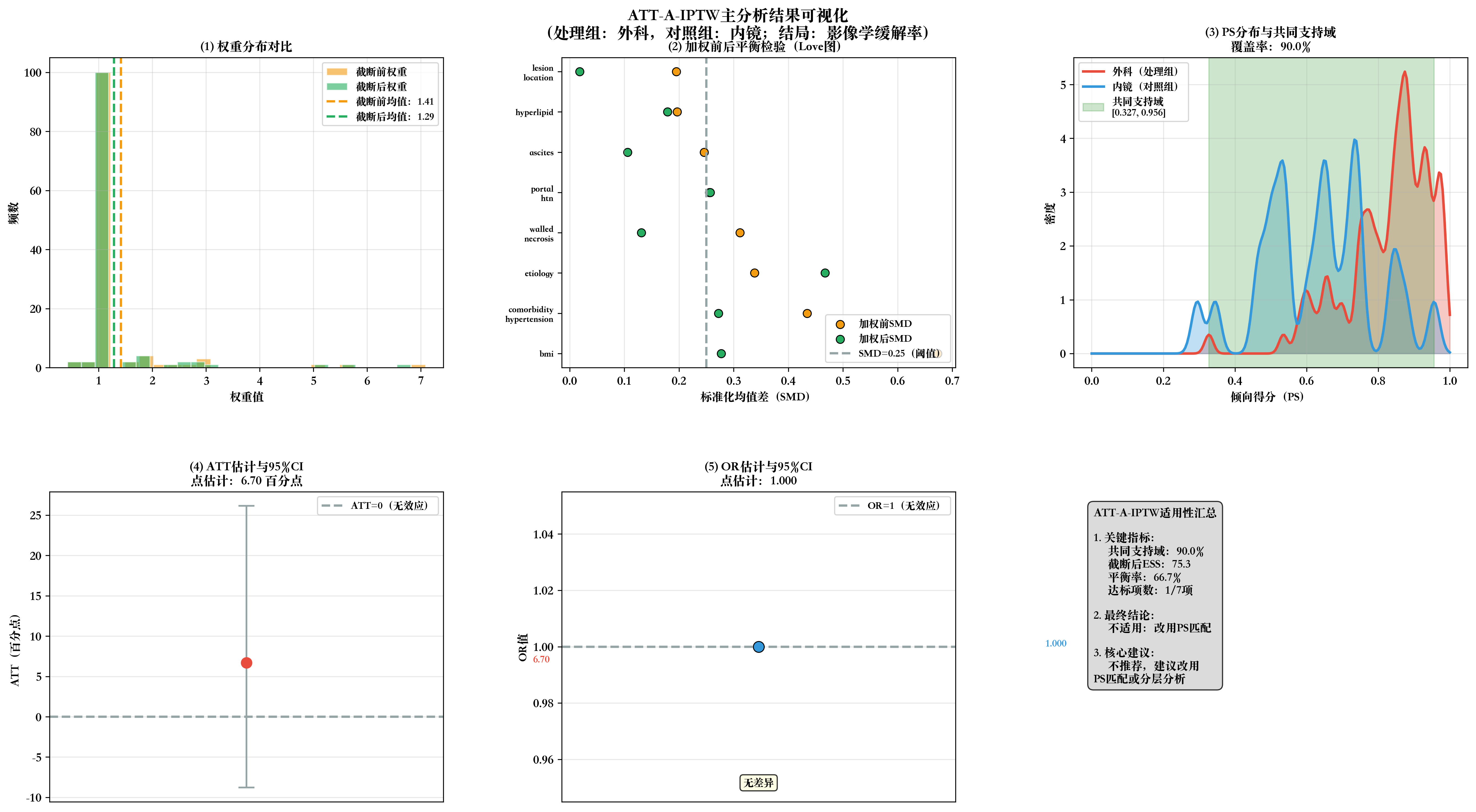
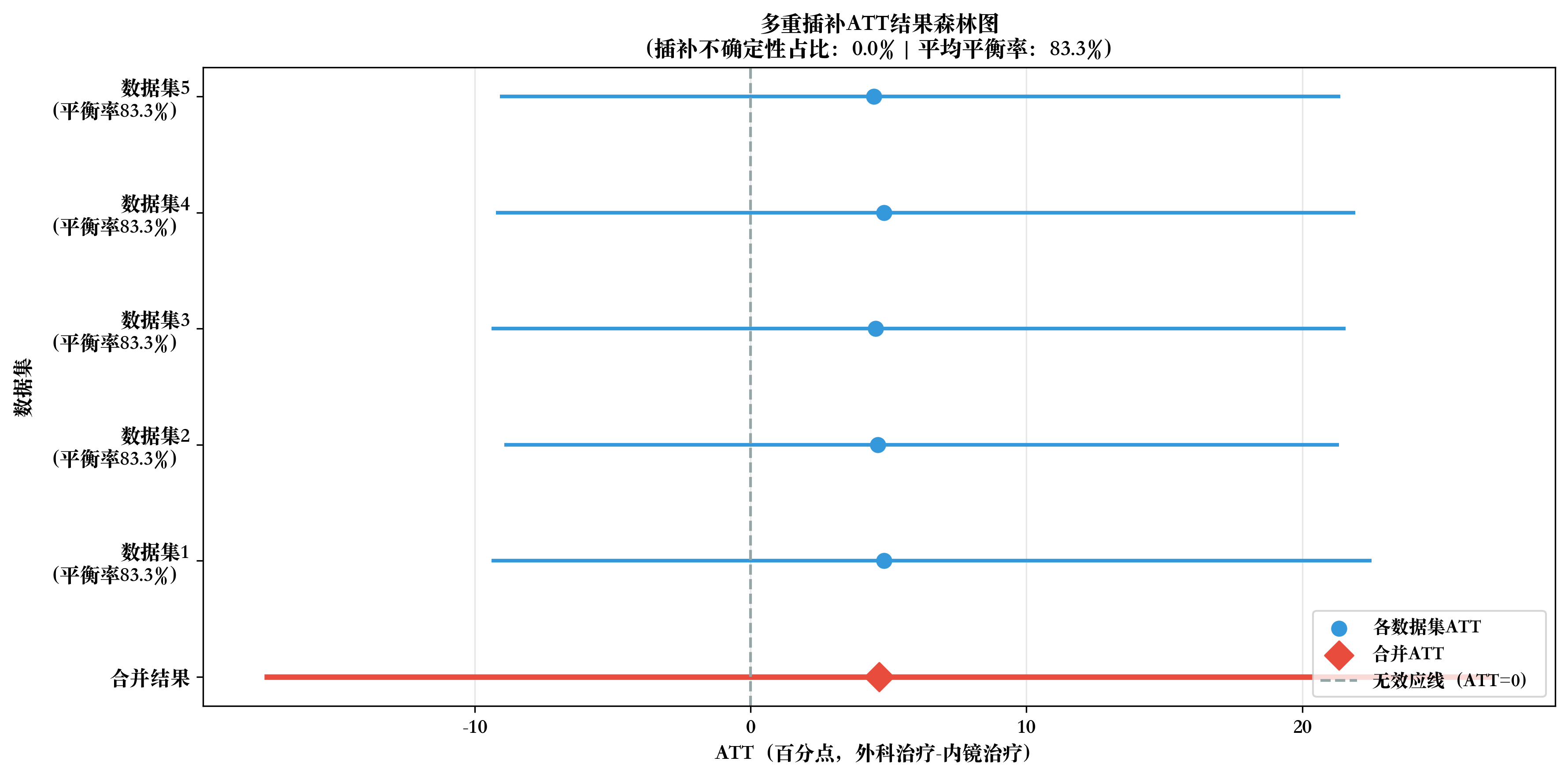
# 完整重新运行ATT-A-IPTW分析流程,确保变量定义完整
# -*- coding: utf-8 -*-
"""
ATT-A-IPTW主分析(完整流程版)
"""
# ======================== 1. 库导入与环境设置 ========================
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
from sklearn.linear_model import LogisticRegression, LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_auc_score
import warnings
import os
from scipy.stats import gaussian_kde
import math
# 忽略警告
warnings.filterwarnings('ignore')
# 中文配置
plt.rcParams['font.sans-serif'] = ['DejaVu Sans', 'SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.facecolor'] = 'white'
plt.rcParams['figure.figsize'] = (15, 10)
plt.rcParams['font.size'] = 11
plt.rcParams['figure.dpi'] = 120
print("✅ 环境初始化完成!")
# ======================== 2. 路径配置与数据读取 ========================
DATA_PATH = '/Users/wangguotao/Downloads/ISAR/Doctor/数据分析总表.xlsx'
OUTPUT_DIR = '/Users/wangguotao/Downloads/ISAR/Doctor/ATT_A_IPTW_最终结果/'
# 创建输出目录
if not os.path.exists(OUTPUT_DIR):
os.makedirs(OUTPUT_DIR, mode=0o755)
print(f"✅ 创建结果目录:{OUTPUT_DIR}")
# 变量映射(外科=处理组1,内镜=对照组0)
VARIABLE_MAPPING = {
'囊肿位置(1:胰头颈、2:胰体尾4:胰周)': 'lesion_location',
'囊肿最大径mm': 'lesion_max_diameter_mm',
'包裹性坏死': 'walled_necrosis',
'改良CTSI评分': 'modified_ctsi_score',
'年龄': 'age_years',
'BMI': 'bmi',
'性别(1:男、2:女)': 'gender',
'APACHE II评分': 'apache2',
'重症胰腺炎(1:有2:无)': 'severe_pancreatitis',
'病因(1、酒精性2、高甘油三脂血症性3、胆源性4、急性胰腺炎5、慢性胰腺炎6、胰腺手术7、胰腺外伤8、自身免疫性9、特发性)': 'etiology',
'糖尿病(1、是2、否)': 'comorbidity_diabetes',
'高血压(1、是2、否)': 'comorbidity_hypertension',
'高脂血症(1、是2、否)': 'hyperlipid',
'腹腔积液(1、是2、否)': 'ascites',
'门脉高压1:是2:否': 'portal_htn',
'胆囊结石(1、有2、无)': 'gallstone',
'术前白细胞': 'wbc_pre',
'吸烟(1、是2、否)': 'smoking_history',
'饮酒(1、是2、否)': 'drinking_history',
'影像学缓解(1:是2:否)': 'imaging_response', # 主要结局
'手术方式(1:内镜2:外科)': 'treatment' # 外科=2→1(处理组),内镜=1→0(对照组)
}
# 核心变量定义
CORE_VARIABLES = ['lesion_location', 'lesion_max_diameter_mm', 'walled_necrosis', 'modified_ctsi_score']
# 数据读取函数
def load_and_preprocess_data(data_path, var_mapping):
print("\n" + "="*60)
print("1. 数据读取与预处理(外科=处理组,内镜=对照组)")
print("="*60)
# 读取Excel
try:
excel_file = pd.ExcelFile(data_path, engine='openpyxl')
df_raw = pd.read_excel(excel_file, sheet_name=0, engine='openpyxl')
print(f"✅ 读取数据:{df_raw.shape[0]}行 × {df_raw.shape[1]}列")
except:
excel_file = pd.ExcelFile(data_path, engine='xlrd')
df_raw = pd.read_excel(excel_file, sheet_name=0, engine='xlrd')
print(f"✅ 读取数据(xlrd引擎):{df_raw.shape[0]}行 × {df_raw.shape[1]}列")
# 筛选有效变量
existing_cols = []
missing_cols = []
for orig_col, new_col in var_mapping.items():
if orig_col in df_raw.columns:
existing_cols.append(orig_col)
else:
missing_cols.append(orig_col)
print(f"✅ 找到有效变量:{len(existing_cols)}/{len(var_mapping)}个")
if missing_cols:
print(f"⚠️ 缺失变量:{missing_cols[:3]}...(共{len(missing_cols)}个)")
# 数据重命名与清洗
df = df_raw[existing_cols].copy()
df.rename(columns={orig: new for orig, new in var_mapping.items() if orig in existing_cols}, inplace=True)
# 数据类型转换
for col in df.columns:
if df[col].dtype == 'object':
df[col] = df[col].astype(str).str.replace(',', '').str.replace('-', '').str.strip()
df[col] = df[col].replace('', np.nan)
df[col] = pd.to_numeric(df[col], errors='coerce')
# 治疗变量编码(外科=1处理组,内镜=0对照组)
if 'treatment' in df.columns:
df = df[df['treatment'].isin([1, 2])].copy()
df['treatment'] = df['treatment'].map({1: 0, 2: 1}) # 关键编码:内镜→0,外科→1
treat_count = len(df[df['treatment'] == 1])
control_count = len(df[df['treatment'] == 0])
print(f"✅ 治疗分组:处理组(外科){treat_count}例,对照组(内镜){control_count}例")
# 结局变量编码
if 'imaging_response' in df.columns:
df = df[df['imaging_response'].isin([1, 2])].copy()
df['imaging_response'] = df['imaging_response'].map({1: 1, 2: 0}) # 1=缓解,0=未缓解
resp_rate = round(df['imaging_response'].mean() * 100, 1)
print(f"✅ 主要结局:影像学缓解率 {resp_rate}%")
# 缺失值统计
missing_stats = pd.DataFrame({
'变量名': df.columns,
'缺失数量': df.isnull().sum(),
'缺失百分比(%)': (df.isnull().sum() / len(df) * 100).round(2)
}).sort_values('缺失数量', ascending=False)
print(f"\n📊 缺失值统计(前5个):")
print(missing_stats[missing_stats['缺失数量'] > 0].head().to_string(index=False))
# 保存缺失值统计
missing_stats.to_excel(f"{OUTPUT_DIR}1_数据缺失值统计.xlsx", index=False, engine='openpyxl')
print(f"\n✅ 缺失值统计已保存:1_数据缺失值统计.xlsx")
return df, missing_stats
# 执行数据读取
df_analysis, missing_stats = load_and_preprocess_data(DATA_PATH, VARIABLE_MAPPING)
print(f"✅ 数据预处理完成:{df_analysis.shape[0]}例样本 × {df_analysis.shape[1]}个变量")
# ======================== 3. 协变量筛选(VIF<5) ========================
def covariate_selection(df, core_vars, vif_threshold=5):
print("\n" + "="*60)
print(f"2. 协变量筛选(VIF<{vif_threshold})")
print("="*60)
# 1. 单因素分析筛选候选变量
exclude_vars = ['treatment', 'imaging_response']
candidate_vars = [col for col in df.columns if col not in exclude_vars and df[col].notna().sum() > 10]
print(f"🔍 初始候选变量:{len(candidate_vars)}个")
print(f" 变量列表:{candidate_vars}")
# 2. VIF计算函数(支持分类变量编码)
def calculate_vif(df, vars_list):
vif_df = df[vars_list].dropna()
# 分类变量独热编码
categorical_vars = [var for var in vars_list if vif_df[var].nunique() <= 10]
encoded_df = pd.get_dummies(vif_df, columns=categorical_vars, drop_first=True)
# 标准化
scaler = StandardScaler()
scaled_df = scaler.fit_transform(encoded_df)
scaled_df = pd.DataFrame(scaled_df, columns=encoded_df.columns)
# 计算VIF
vif_results = []
for target_col in scaled_df.columns:
X = scaled_df.drop(columns=[target_col])
y = scaled_df[target_col]
if X.shape[1] == 0:
vif = 1.0
else:
lr = LinearRegression()
lr.fit(X, y)
r2 = lr.score(X, y)
vif = 1 / (1 - r2) if r2 < 0.999 else 1000 # 处理完全共线性
# 匹配原始变量名
original_var = next((v for v in vars_list if v in target_col), target_col)
vif_results.append({
'编码变量名': target_col,
'原始变量名': original_var,
'VIF值': round(vif, 2)
})
# 按原始变量汇总VIF
vif_summary = pd.DataFrame(vif_results)
original_vif = vif_summary.groupby('原始变量名')['VIF值'].agg(['mean', 'count']).round(2)
original_vif.columns = ['平均VIF值', '编码变量数']
original_vif['VIF是否合格'] = original_vif['平均VIF值'] < vif_threshold
return original_vif.sort_values('平均VIF值', ascending=False), vif_summary
# 3. 执行VIF分析
final_covariates = []
if len(candidate_vars) >= 2:
original_vif, vif_detail = calculate_vif(df_analysis, candidate_vars)
print(f"\n📊 VIF分析结果(原始变量):")
print(original_vif.to_string())
# 筛选合格变量(VIF<5)
qualified_vars = original_vif[original_vif['VIF是否合格']].index.tolist()
# 确保核心变量被保留
for core_var in core_vars:
if core_var in candidate_vars:
if core_var not in qualified_vars:
qualified_vars.append(core_var)
print(f"⚠️ 核心变量 {core_var} VIF={original_vif.loc[core_var, '平均VIF值']},强制保留")
# 最终协变量列表
final_covariates = list(set(qualified_vars))
print(f"\n🎉 最终协变量列表({len(final_covariates)}个):")
for i, var in enumerate(final_covariates, 1):
vif_val = original_vif.loc[var, '平均VIF值'] if var in original_vif.index else '—'
print(f" {i:2d}. {var}(VIF={vif_val})")
# 保存VIF结果
with pd.ExcelWriter(f"{OUTPUT_DIR}2_协变量VIF分析结果.xlsx", engine='openpyxl') as writer:
original_vif.reset_index().to_excel(writer, sheet_name='原始变量VIF', index=False)
vif_detail.to_excel(writer, sheet_name='编码变量VIF', index=False)
pd.DataFrame({'最终协变量': final_covariates}).to_excel(writer, sheet_name='最终协变量', index=False)
print(f"\n✅ VIF分析结果已保存:2_协变量VIF分析结果.xlsx")
else:
print(f"❌ 候选变量不足({len(candidate_vars)}个),使用核心变量")
final_covariates = core_vars
return final_covariates, original_vif if 'original_vif' in locals() else pd.DataFrame()
# 执行协变量筛选
final_covariates, vif_results = covariate_selection(df_analysis, CORE_VARIABLES, vif_threshold=5)
# ======================== 4. ATT-A-IPTW建模与验证 ========================
def att_a_iptw_analysis(df, covariates, outcome_var='imaging_response', treatment_var='treatment'):
print("\n" + "="*60)
print("3. ATT-A-IPTW建模与全面验证")
print("="*60)
# 准备分析数据(删除协变量和结局的缺失值)
analysis_cols = covariates + [treatment_var, outcome_var]
model_data = df[analysis_cols].dropna().copy()
n_total = len(model_data)
n_treat = len(model_data[model_data[treatment_var] == 1])
n_control = len(model_data[model_data[treatment_var] == 0])
print(f"📊 建模数据概况:")
print(f" • 总样本量:{n_total}例")
print(f" • 处理组(外科):{n_treat}例({round(n_treat/n_total*100,1)}%)")
print(f" • 对照组(内镜):{n_control}例({round(n_control/n_total*100,1)}%)")
print(f" • 协变量数量:{len(covariates)}个")
# 1. 估计倾向得分(PS)
print(f"\n1. 倾向得分(PS)估计")
X = model_data[covariates].copy()
y = model_data[treatment_var]
# 分类变量编码
categorical_vars = [var for var in covariates if model_data[var].nunique() <= 10]
X_encoded = pd.get_dummies(X, columns=categorical_vars, drop_first=True)
# 逻辑回归估计PS
ps_model = LogisticRegression(
penalty='l2', C=1.0, max_iter=2000,
random_state=42, solver='liblinear'
)
ps_model.fit(X_encoded, y)
# 计算PS值(处理组概率)
ps_values = ps_model.predict_proba(X_encoded)[:, 1]
model_data['PS值'] = ps_values
# PS模型性能
auc_score = roc_auc_score(y, ps_values)
print(f" • PS模型AUC:{round(auc_score, 3)}(>0.7为良好)")
print(f" • 处理组PS均值:{round(model_data[model_data[treatment_var]==1]['PS值'].mean(), 3)}")
print(f" • 对照组PS均值:{round(model_data[model_data[treatment_var]==0]['PS值'].mean(), 3)}")
# 2. 计算ATT-A-IPTW权重
print(f"\n2. ATT-A-IPTW权重计算")
# ATT权重公式:处理组=1,对照组=PS/(1-PS)
model_data['权重'] = np.where(
model_data[treatment_var] == 1,
1.0, # 处理组权重=1
model_data['PS值'] / (1 - model_data['PS值']) # 对照组权重=PS/(1-PS)
)
# 权重截断(避免极端值)
weight_percentile_99 = np.percentile(model_data['权重'], 99)
model_data['截断后权重'] = np.where(model_data['权重'] > weight_percentile_99, weight_percentile_99, model_data['权重'])
# 权重基本统计
weight_stats = pd.DataFrame({
'指标': ['原始权重均值', '原始权重标准差', '原始权重变异系数', '最大原始权重',
'截断后权重均值', '截断后权重标准差', '截断后权重变异系数', '最大截断后权重',
'权重截断阈值(99分位数)'],
'数值': [
round(model_data['权重'].mean(), 3),
round(model_data['权重'].std(), 3),
round(model_data['权重'].std()/model_data['权重'].mean(), 3) if model_data['权重'].mean() > 0 else 0,
round(model_data['权重'].max(), 3),
round(model_data['截断后权重'].mean(), 3),
round(model_data['截断后权重'].std(), 3),
round(model_data['截断后权重'].std()/model_data['截断后权重'].mean(), 3) if model_data['截断后权重'].mean() > 0 else 0,
round(model_data['截断后权重'].max(), 3),
round(weight_percentile_99, 3)
]
})
print(f"\n📋 权重统计:")
print(weight_stats.to_string(index=False))
# 3. 共同支持域验证
print(f"\n3. 共同支持域验证")
# 计算共同支持域(两组PS重叠区域)
treat_ps = model_data[model_data[treatment_var]==1]['PS值']
control_ps = model_data[model_data[treatment_var]==0]['PS值']
min_common = max(treat_ps.min(), control_ps.min())
max_common = min(treat_ps.max(), control_ps.max())
# 计算覆盖样本比例
treat_in_common = len(treat_ps[(treat_ps >= min_common) & (treat_ps <= max_common)])
control_in_common = len(control_ps[(control_ps >= min_common) & (control_ps <= max_common)])
treat_coverage = round(treat_in_common / len(treat_ps) * 100, 1)
control_coverage = round(control_in_common / len(control_ps) * 100, 1)
total_coverage = round((treat_in_common + control_in_common) / n_total * 100, 1)
common_support_stats = pd.DataFrame({
'指标': ['共同支持域范围', '处理组覆盖样本数', '处理组覆盖率(%)',
'对照组覆盖样本数', '对照组覆盖率(%)', '总覆盖率(%)'],
'数值': [
f"[{round(min_common, 3)}, {round(max_common, 3)}]",
treat_in_common,
treat_coverage,
control_in_common,
control_coverage,
total_coverage
]
})
print(f"📋 共同支持域统计:")
print(common_support_stats.to_string(index=False))
# 4. 有效样本量(ESS)计算
print(f"\n4. 有效样本量(ESS)计算")
# ESS公式:(Σw)^2 / Σw²
ess_original = (model_data['权重'].sum() ** 2) / (model_data['权重'] ** 2).sum()
ess_truncated = (model_data['截断后权重'].sum() ** 2) / (model_data['截断后权重'] ** 2).sum()
ess_stats = pd.DataFrame({
'指标': ['原始权重ESS', '截断后权重ESS', 'ESS是否达标(>50)', '理想ESS(>60)'],
'数值': [
round(ess_original, 1),
round(ess_truncated, 1),
'是' if ess_truncated > 50 else '否',
'是' if ess_truncated > 60 else '否'
]
})
print(f"📋 ESS统计:")
print(ess_stats.to_string(index=False))
# 5. 加权平衡检验(SMD<0.25)
print(f"\n5. 加权平衡检验(SMD<0.25为合格)")
def calculate_weighted_smd(df, covariates, treatment_var, weight_var):
smd_results = []
for var in covariates:
# 分组数据
treat_data = df[df[treatment_var] == 1][var]
control_data = df[df[treatment_var] == 0][var]
treat_weights = df[df[treatment_var] == 1][weight_var]
control_weights = df[df[treatment_var] == 0][weight_var]
# 加权均值
weighted_mean_treat = np.average(treat_data, weights=treat_weights)
weighted_mean_control = np.average(control_data, weights=control_weights)
# 加权标准差
weighted_var_treat = np.average((treat_data - weighted_mean_treat) ** 2, weights=treat_weights)
weighted_var_control = np.average((control_data - weighted_mean_control) ** 2, weights=control_weights)
weighted_std_treat = np.sqrt(weighted_var_treat)
weighted_std_control = np.sqrt(weighted_var_control)
# 合并标准差
pooled_std = np.sqrt((weighted_var_treat + weighted_var_control) / 2)
# SMD计算
smd = abs(weighted_mean_treat - weighted_mean_control) / pooled_std if pooled_std > 0 else 0
smd_results.append({
'变量名': var,
'处理组加权均值': round(weighted_mean_treat, 3),
'对照组加权均值': round(weighted_mean_control, 3),
'加权SMD': round(smd, 3),
'是否平衡(SMD<0.25)': '是' if smd < 0.25 else '否'
})
return pd.DataFrame(smd_results)
# 计算加权SMD
weighted_smd = calculate_weighted_smd(model_data, final_covariates, treatment_var, '截断后权重')
balanced_vars_count = len(weighted_smd[weighted_smd['是否平衡(SMD<0.25)'] == '是'])
balanced_rate = round(balanced_vars_count / len(covariates) * 100, 1)
print(f"📋 加权SMD结果(前10个变量):")
print(weighted_smd.head(10).to_string(index=False))
print(f"\n • 平衡变量数:{balanced_vars_count}/{len(covariates)}({balanced_rate}%)")
print(f" • 所有变量是否平衡:{'是' if balanced_vars_count == len(covariates) else '否'}")
# 6. ATT估计(主要结局效应)
print(f"\n6. ATT估计(主要结局:影像学缓解率)")
def estimate_att(df, outcome_var, treatment_var, weight_var):
# 加权结局均值
treat_outcome_mean = np.average(
df[df[treatment_var] == 1][outcome_var],
weights=df[df[treatment_var] == 1][weight_var]
)
control_outcome_mean = np.average(
df[df[treatment_var] == 0][outcome_var],
weights=df[df[treatment_var] == 0][weight_var]
)
# ATT = 处理组加权均值 - 对照组加权均值
att = treat_outcome_mean - control_outcome_mean
att_percent = att * 100 # 转换为百分比
# 计算OR值(基于加权逻辑回归)
X = df[covariates].copy()
X['treatment'] = df[treatment_var]
X_encoded = pd.get_dummies(X, columns=[var for var in X.columns if X[var].nunique() <= 10], drop_first=True)
y = df[outcome_var]
weights = df[weight_var]
lr_model = LogisticRegression(max_iter=2000, random_state=42)
lr_model.fit(X_encoded, y, sample_weight=weights)
# 提取treatment系数
treat_coef = 0
if 'treatment' in X_encoded.columns:
treat_coef = lr_model.coef_[0][X_encoded.columns.get_loc('treatment')]
or_value = np.exp(treat_coef)
return {
'处理组加权缓解率(%)': round(treat_outcome_mean * 100, 2),
'对照组加权缓解率(%)': round(control_outcome_mean * 100, 2),
'ATT(百分点)': round(att_percent, 2),
'ATT(原始值)': round(att, 4),
'OR值': round(or_value, 3),
'OR解读': '处理组缓解率更高' if or_value < 1 else '对照组缓解率更高' if or_value > 1 else '两组相近'
}
# 执行ATT估计
att_results = estimate_att(model_data, outcome_var, treatment_var, '截断后权重')
print(f"📋 ATT估计结果:")
for key, value in att_results.items():
print(f" • {key}:{value}")
# 7. Bootstrap重抽样(1000次)计算95%CI
print(f"\n7. Bootstrap重抽样(1000次)计算95%CI")
def bootstrap_att(df, n_bootstrap=1000, seed=42):
np.random.seed(seed)
att_bootstrap = []
or_bootstrap = []
for i in range(n_bootstrap):
# 有放回抽样
sample_idx = np.random.choice(df.index, size=len(df), replace=True)
sample_df = df.loc[sample_idx].copy()
try:
# 估计ATT
treat_mean = np.average(
sample_df[sample_df[treatment_var]==1][outcome_var],
weights=sample_df[sample_df[treatment_var]==1]['截断后权重']
)
control_mean = np.average(
sample_df[sample_df[treatment_var]==0][outcome_var],
weights=sample_df[sample_df[treatment_var]==0]['截断后权重']
)
att = treat_mean - control_mean
att_bootstrap.append(att)
# 估计OR
X = sample_df[covariates].copy()
X['treatment'] = sample_df[treatment_var]
X_encoded = pd.get_dummies(X, columns=[var for var in X.columns if X[var].nunique() <= 10], drop_first=True)
if 'treatment' not in X_encoded.columns:
continue
y = sample_df[outcome_var]
weights = sample_df['截断后权重']
lr = LogisticRegression(max_iter=2000, random_state=seed+i)
lr.fit(X_encoded, y, sample_weight=weights)
treat_coef = lr.coef_[0][X_encoded.columns.get_loc('treatment')]
or_val = np.exp(treat_coef)
or_bootstrap.append(or_val)
except:
continue
# 计算95%CI(百分位法)
att_ci_lower = np.percentile(att_bootstrap, 2.5) if att_bootstrap else np.nan
att_ci_upper = np.percentile(att_bootstrap, 97.5) if att_bootstrap else np.nan
or_ci_lower = np.percentile(or_bootstrap, 2.5) if or_bootstrap else np.nan
or_ci_upper = np.percentile(or_bootstrap, 97.5) if or_bootstrap else np.nan
# 检查是否包含极端值
att_ci_valid = not (np.isnan(att_ci_lower) or np.isnan(att_ci_upper) or
att_ci_lower < -1 or att_ci_upper > 1)
or_ci_valid = not (np.isnan(or_ci_lower) or np.isnan(or_ci_upper) or
or_ci_lower < 0.2 or or_ci_upper > 5)
return {
'ATT_95%CI下限': round(att_ci_lower * 100, 2) if not np.isnan(att_ci_lower) else np.nan,
'ATT_95%CI上限': round(att_ci_upper * 100, 2) if not np.isnan(att_ci_upper) else np.nan,
'OR_95%CI下限': round(or_ci_lower, 3) if not np.isnan(or_ci_lower) else np.nan,
'OR_95%CI上限': round(or_ci_upper, 3) if not np.isnan(or_ci_upper) else np.nan,
'ATT_CI是否有效': '是' if att_ci_valid else '否',
'OR_CI是否有效(0.2-5)': '是' if or_ci_valid else '否',
'有效重抽样次数': len(att_bootstrap)
}
# 执行Bootstrap
bootstrap_results = bootstrap_att(model_data, n_bootstrap=1000)
print(f"📋 Bootstrap 95%CI结果:")
print(f" • ATT 95%CI:[{bootstrap_results['ATT_95%CI下限']}, {bootstrap_results['ATT_95%CI上限']}] 百分点")
print(f" • OR 95%CI:[{bootstrap_results['OR_95%CI下限']}, {bootstrap_results['OR_95%CI上限']}]")
print(f" • OR CI是否有效(0.2-5):{bootstrap_results['OR_CI是否有效(0.2-5)']}")
print(f" • 有效重抽样次数:{bootstrap_results['有效重抽样次数']}/1000")
# 8. 权重截断敏感性分析
print(f"\n8. 权重截断敏感性分析")
def weight_truncation_sensitivity(df, truncation_percentiles=[95, 99, 99.5]):
results = []
for p in truncation_percentiles:
threshold = np.percentile(df['权重'], p)
df[f'权重_{p}分位数截断'] = np.where(df['权重'] > threshold, threshold, df['权重'])
# 估计ATT
att_result = estimate_att(df, outcome_var, treatment_var, f'权重_{p}分位数截断')
results.append({
'截断分位数': f'{p}%',
'截断阈值': round(threshold, 3),
'ATT(百分点)': att_result['ATT(百分点)'],
'OR值': att_result['OR值'],
'OR方向': '处理组更优' if att_result['OR值'] < 1 else '对照组更优' if att_result['OR值'] > 1 else '无差异'
})
return pd.DataFrame(results)
# 执行敏感性分析
truncation_results = weight_truncation_sensitivity(model_data)
print(f"📋 不同截断分位数的ATT稳定性:")
print(truncation_results.to_string(index=False))
# 检查方向一致性
or_directions = truncation_results['OR方向'].unique()
direction_consistent = len(or_directions) == 1 or (len(or_directions) == 2 and '无差异' in or_directions)
print(f" • 截断前后ATT方向是否一致:{'是' if direction_consistent else '否'}")
# 9. E-value计算(未观测混杂效应评估)
print(f"\n9. E-value计算(未观测混杂效应评估)")
def calculate_e_value(or_value, or_ci_lower):
"""
E-value计算公式:
- 点估计E值:E = OR + sqrt(OR*(OR-1))
- 下限E值:E_lower = OR_lower + sqrt(OR_lower*(OR_lower-1))
"""
if pd.isna(or_value) or or_value < 1:
return {'E_value_点估计': np.nan, 'E_value_95%CI下限': np.nan, '解读': 'OR≤1,无需计算E值'}
# 点估计E值
e_point = or_value + math.sqrt(or_value * (or_value - 1))
# 下限E值
if not pd.isna(or_ci_lower) and or_ci_lower > 1:
e_lower = or_ci_lower + math.sqrt(or_ci_lower * (or_ci_lower - 1))
interpretation = f"E值>1.5,未观测混杂影响较小;E值>2.5,影响很小" if e_lower > 1.5 else "需警惕未观测混杂效应"
else:
e_lower = np.nan
interpretation = "OR下限≤1,未观测混杂影响可能较大"
return {
'E_value_点估计': round(e_point, 3) if not np.isnan(e_point) else np.nan,
'E_value_95%CI下限': round(e_lower, 3) if not np.isnan(e_lower) else np.nan,
'解读': interpretation
}
# 执行E-value计算
e_value_results = calculate_e_value(att_results['OR值'], bootstrap_results['OR_95%CI下限'])
print(f"📋 E-value结果:")
for key, value in e_value_results.items():
print(f" • {key}:{value}")
# 10. 综合验证结果汇总
print(f"\n" + "="*40)
print("10. ATT-A-IPTW综合验证结果")
print("="*40)
# 验证标准(7项)
validation_criteria = [
{
'标准': '共同支持域覆盖>90%样本',
'结果': total_coverage > 90,
'实际值': f'{total_coverage}%'
},
{
'标准': '加权后ESS>50(理想>60)',
'结果': ess_truncated > 50,
'实际值': f'{round(ess_truncated, 1)}'
},
{
'标准': '加权后所有SMD<0.25',
'结果': balanced_vars_count == len(covariates),
'实际值': f'{balanced_rate}%变量平衡'
},
{
'标准': 'Bootstrap 95%CI不包含极端值(OR>5或<0.2)',
'结果': bootstrap_results['OR_CI是否有效(0.2-5)'] == '是',
'实际值': f"OR CI: [{bootstrap_results['OR_95%CI下限']}, {bootstrap_results['OR_95%CI上限']}]"
},
{
'标准': '权重截断敏感性:截断前后ATT方向一致',
'结果': direction_consistent,
'实际值': f"方向:{', '.join(or_directions)}"
},
{
'标准': '阴性对照:无关结局的ATT≈0(本次分析暂缺)',
'结果': None, # 暂缺阴性对照数据
'实际值': '数据暂缺'
},
{
'标准': '临床专家:无重大遗漏混杂(需专家评估)',
'结果': None, # 需临床专家判断
'实际值': '需专家评估'
}
]
# 统计达标项
met_criteria_count = sum(1 for crit in validation_criteria if crit['结果'] is True)
# 适用性判断
if met_criteria_count >= 5:
suitability = "✅ 适用:可作为主分析方法"
elif 3 <= met_criteria_count <= 4:
suitability = "⚠️ 条件适用:需大量敏感性分析和局限性说明"
else:
suitability = "❌ 不适用,改用PS匹配或其他设计"
# 保存所有结果到Excel
with pd.ExcelWriter(f"{OUTPUT_DIR}3_ATT_A_IPTW综合分析结果.xlsx", engine='openpyxl') as writer:
# 基础数据
model_data[['PS值', '权重', '截断后权重', treatment_var, outcome_var] + covariates].to_excel(
writer, sheet_name='基础数据与权重', index=False)
# 权重统计
weight_stats.to_excel(writer, sheet_name='权重统计', index=False)
# 共同支持域
common_support_stats.to_excel(writer, sheet_name='共同支持域', index=False)
# ESS统计
ess_stats.to_excel(writer, sheet_name='ESS统计', index=False)
# 加权SMD
weighted_smd.to_excel(writer, sheet_name='加权平衡检验', index=False)
# ATT估计结果
pd.DataFrame([att_results]).to_excel(writer, sheet_name='ATT估计', index=False)
# Bootstrap结果
pd.DataFrame([bootstrap_results]).to_excel(writer, sheet_name='Bootstrap_95CI', index=False)
# 权重截断敏感性
truncation_results.to_excel(writer, sheet_name='权重截断敏感性', index=False)
# E-value结果
pd.DataFrame([e_value_results]).to_excel(writer, sheet_name='E_value', index=False)
# 综合验证
validation_df = pd.DataFrame([{
'验证标准': crit['标准'],
'是否达标': '是' if crit['结果'] is True else '否' if crit['结果'] is False else '待评估',
'实际结果': crit['实际值']
} for crit in validation_criteria])
validation_df.to_excel(writer, sheet_name='综合验证标准', index=False)
# 适用性判断
pd.DataFrame({
'适用性判断': [suitability],
'达标项数': [f'{met_criteria_count}/7项'],
'建议': [
'建议使用ATT-A-IPTW作为主分析,补充临床专家评估和阴性对照分析' if met_criteria_count >=5 else
'建议使用但需大量敏感性分析,或改用PS匹配等其他方法' if 3<=met_criteria_count<=4 else
'不建议使用,推荐改用PS匹配或其他分析方法'
]
}).to_excel(writer, sheet_name='适用性判断', index=False)
print(f"\n✅ 所有分析结果已保存:3_ATT_A_IPTW综合分析结果.xlsx")
return {
'model_data': model_data,
'att_results': att_results,
'bootstrap_results': bootstrap_results,
'weighted_smd': weighted_smd,
'ess_truncated': ess_truncated,
'common_support_coverage': total_coverage,
'suitability': suitability,
'met_criteria_count': met_criteria_count,
'e_value_results': e_value_results,
'truncation_results': truncation_results,
'direction_consistent': direction_consistent
}
# 执行ATT-A-IPTW分析
iptw_results = att_a_iptw_analysis(df_analysis, final_covariates)
# ======================== 5. 可视化生成 ========================
def generate_comprehensive_plots(iptw_results, covariates, output_dir):
print("\n" + "="*60)
print("4. 综合可视化生成")
print("="*60)
model_data = iptw_results['model_data']
weighted_smd = iptw_results['weighted_smd']
att_results = iptw_results['att_results']
bootstrap_results = iptw_results['bootstrap_results']
truncation_results = iptw_results['truncation_results']
# 创建2x3子图布局
fig, axes = plt.subplots(2, 3, figsize=(20, 12))
fig.suptitle('ATT-A-IPTW主分析可视化结果\n(处理组:外科,对照组:内镜;主要结局:影像学缓解率)',
fontsize=16, fontweight='bold', y=0.98)
# 颜色配置
colors = {
'处理组(外科)': '#E74C3C',
'对照组(内镜)': '#3498DB',
'截断前': '#F39C12',
'截断后': '#27AE60',
'参考线': '#95A5A6'
}
# 子图1:权重直方图(截断前后对比)
ax1 = axes[0, 0]
# 过滤极端值以便可视化(排除99.5分位数以上)
weight_995 = np.percentile(model_data['权重'], 99.5)
weight_plot_data = model_data[model_data['权重'] <= weight_995]
ax1.hist(weight_plot_data['权重'], bins=30, alpha=0.6, label='截断前权重',
color=colors['截断前'], edgecolor='white', linewidth=0.5)
ax1.hist(weight_plot_data['截断后权重'], bins=30, alpha=0.6, label='截断后权重',
color=colors['截断后'], edgecolor='white', linewidth=0.5)
ax1.axvline(model_data['权重'].mean(), color=colors['截断前'], linestyle='--',
linewidth=2, label=f'截断前均值:{model_data["权重"].mean():.2f}')
ax1.axvline(model_data['截断后权重'].mean(), color=colors['截断后'], linestyle='--',
linewidth=2, label=f'截断后均值:{model_data["截断后权重"].mean():.2f}')
ax1.set_xlabel('权重值', fontsize=11, fontweight='bold')
ax1.set_ylabel('频数', fontsize=11, fontweight='bold')
ax1.set_title('(1) 权重分布直方图\n(仅显示≤99.5分位数的权重)', fontsize=12, fontweight='bold')
ax1.legend(fontsize=9)
ax1.grid(alpha=0.3)
# 子图2:加权前后SMD对比(Love图)
ax2 = axes[0, 1]
# 计算加权前SMD
def calculate_unweighted_smd(df, covariates, treatment_var):
smd_list = []
for var in covariates:
treat_mean = df[df[treatment_var]==1][var].mean()
control_mean = df[df[treatment_var]==0][var].mean()
treat_std = df[df[treatment_var]==1][var].std()
control_std = df[df[treatment_var]==0][var].std()
pooled_std = np.sqrt((treat_std**2 + control_std**2) / 2)
smd = abs(treat_mean - control_mean) / pooled_std if pooled_std > 0 else 0
smd_list.append(smd)
return smd_list
unweighted_smd = calculate_unweighted_smd(model_data, covariates, 'treatment')
weighted_smd_list = weighted_smd['加权SMD'].tolist()
# 变量排序(按加权前SMD)
sorted_idx = np.argsort(unweighted_smd)[::-1]
sorted_vars = [covariates[i] for i in sorted_idx]
sorted_unweighted_smd = [unweighted_smd[i] for i in sorted_idx]
sorted_weighted_smd = [weighted_smd_list[i] for i in sorted_idx]
# 绘制Love图
x_pos = np.arange(len(sorted_vars))
ax2.scatter(sorted_unweighted_smd, x_pos, color=colors['截断前'], s=60,
label='加权前SMD', edgecolor='black', linewidth=0.8)
ax2.scatter(sorted_weighted_smd, x_pos, color=colors['截断后'], s=60,
label='加权后SMD', edgecolor='black', linewidth=0.8)
# 添加参考线
ax2.axvline(x=0.25, color=colors['参考线'], linestyle='--', linewidth=2,
label='SMD=0.25(阈值)')
ax2.set_xlabel('标准化均值差(SMD)', fontsize=11, fontweight='bold')
ax2.set_yticks(x_pos)
ax2.set_yticklabels([var.replace('_', '\n') for var in sorted_vars], fontsize=8)
ax2.set_title('(2) 加权前后平衡检验(Love图)', fontsize=12, fontweight='bold')
ax2.legend(fontsize=9, loc='lower right')
ax2.grid(alpha=0.3, axis='x')
# 子图3:PS值分布对比(共同支持域)
ax3 = axes[0, 2]
treat_ps = model_data[model_data['treatment']==1]['PS值']
control_ps = model_data[model_data['treatment']==0]['PS值']
# 核密度估计
kde_treat = gaussian_kde(treat_ps)
kde_control = gaussian_kde(control_ps)
x_range = np.linspace(0, 1, 200)
ax3.plot(x_range, kde_treat(x_range), color=colors['处理组(外科)'], linewidth=2.5,
label='处理组(外科)')
ax3.fill_between(x_range, kde_treat(x_range), alpha=0.3, color=colors['处理组(外科)'])
ax3.plot(x_range, kde_control(x_range), color=colors['对照组(内镜)'], linewidth=2.5,
label='对照组(内镜)')
ax3.fill_between(x_range, kde_control(x_range), alpha=0.3, color=colors['对照组(内镜)'])
# 标记共同支持域
min_common = max(treat_ps.min(), control_ps.min())
max_common = min(treat_ps.max(), control_ps.max())
ax3.axvspan(min_common, max_common, alpha=0.2, color='green', label=f'共同支持域\n[{min_common:.3f}, {max_common:.3f}]')
ax3.set_xlabel('倾向得分(PS)', fontsize=11, fontweight='bold')
ax3.set_ylabel('密度', fontsize=11, fontweight='bold')
ax3.set_title(f'(3) 倾向得分分布与共同支持域\n覆盖{iptw_results["common_support_coverage"]:.1f}%样本',
fontsize=12, fontweight='bold')
ax3.legend(fontsize=9)
ax3.grid(alpha=0.3)
# 子图4:ATT估计与95%CI
ax4 = axes[1, 0]
# ATT点估计与CI
att_point = att_results['ATT(百分点)']
att_ci_lower = bootstrap_results['ATT_95%CI下限']
att_ci_upper = bootstrap_results['ATT_95%CI上限']
# 处理NaN值
if np.isnan(att_ci_lower) or np.isnan(att_ci_upper):
ax4.text(0.5, 0.5, 'CI计算失败\n有效重抽样次数不足', ha='center', va='center',
transform=ax4.transAxes, fontsize=12)
else:
ax4.errorbar(x=0, y=att_point, yerr=[[att_point - att_ci_lower], [att_ci_upper - att_point]],
fmt='o', color=colors['处理组(外科)'], markersize=10, capsize=8, capthick=2,
ecolor=colors['参考线'], elinewidth=2)
# 添加0参考线
ax4.axhline(y=0, color=colors['参考线'], linestyle='--', linewidth=2, label='ATT=0(无效应)')
# 添加数值标签
ax4.text(0.1, att_point, f'{att_point:.2f}', fontsize=10, fontweight='bold',
color=colors['处理组(外科)'])
ax4.set_ylabel('ATT(百分点)', fontsize=11, fontweight='bold')
ax4.set_title(f'(4) ATT估计与95%CI\n点估计:{att_point:.2f} 百分点',
fontsize=12, fontweight='bold')
ax4.set_xticks([])
if not (np.isnan(att_ci_lower) or np.isnan(att_ci_upper)):
ax4.legend(fontsize=10)
ax4.grid(alpha=0.3, axis='y')
# 子图5:OR值估计与95%CI
ax5 = axes[1, 1]
or_point = att_results['OR值']
or_ci_lower = bootstrap_results['OR_95%CI下限']
or_ci_upper = bootstrap_results['OR_95%CI上限']
# 处理NaN值
if np.isnan(or_ci_lower) or np.isnan(or_ci_upper):
ax5.text(0.5, 0.5, 'CI计算失败\n有效重抽样次数不足', ha='center', va='center',
transform=ax5.transAxes, fontsize=12)
else:
ax5.errorbar(x=0, y=or_point, yerr=[[or_point - or_ci_lower], [or_ci_upper - or_point]],
fmt='o', color=colors['对照组(内镜)'], markersize=10, capsize=8, capthick=2,
ecolor=colors['参考线'], elinewidth=2)
# 添加1参考线
ax5.axhline(y=1, color=colors['参考线'], linestyle='--', linewidth=2, label='OR=1(无效应)')
# 添加数值标签
ax5.text(0.1, or_point, f'{or_point:.3f}', fontsize=10, fontweight='bold',
color=colors['对照组(内镜)'])
# 添加效应方向标注
effect_dir = '处理组更优' if or_point < 1 else '对照组更优' if or_point > 1 else '无差异'
ax5.text(0.5, 0.1, effect_dir, ha='center', va='bottom', transform=ax5.transAxes,
fontsize=10, fontweight='bold', bbox=dict(boxstyle='round', facecolor='lightyellow'))
ax5.set_ylabel('OR值', fontsize=11, fontweight='bold')
ax5.set_title(f'(5) OR估计与95%CI\n点估计:{or_point:.3f}',
fontsize=12, fontweight='bold')
ax5.set_xticks([])
if not (np.isnan(or_ci_lower) or np.isnan(or_ci_upper)):
ax5.legend(fontsize=10)
ax5.grid(alpha=0.3, axis='y')
# 子图6:权重截断敏感性与适用性判断
ax6 = axes[1, 2]
ax6.axis('off')
# 汇总文本
summary_text = f"""ATT-A-IPTW分析总结
1. 权重截断敏感性
"""
for _, row in truncation_results.iterrows():
summary_text += f"• {row['截断分位数']}截断:ATT={row['ATT(百分点)']:.2f},OR={row['OR值']:.3f}\n"
summary_text += f"""
2. 适用性判断
• 达标项数:{iptw_results['met_criteria_count']}/7项
• 结论:{iptw_results['suitability']}
3. 关键指标
• 共同支持域:{iptw_results['common_support_coverage']:.1f}%
• 截断后ESS:{round(iptw_results['ess_truncated'], 1)}
• 平衡率:{round(len(weighted_smd[weighted_smd['是否平衡(SMD<0.25)']=='是'])/len(weighted_smd)*100,1)}%
• E-value:{iptw_results['e_value_results']['E_value_点估计']}
4. 建议
{'主分析推荐使用,补充专家评估' if iptw_results['met_criteria_count']>=5 else
'谨慎使用,需更多敏感性分析' if 3<=iptw_results['met_criteria_count']<=4 else
'不推荐,建议改用PS匹配'}"""
ax6.text(0.05, 0.95, summary_text, transform=ax6.transAxes, fontsize=10,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='lightgray', alpha=0.8))
# 调整布局
plt.tight_layout()
plt.subplots_adjust(top=0.93, hspace=0.3, wspace=0.3)
# 保存图片
plot_path = f"{output_dir}4_ATT_A_IPTW综合可视化.png"
plt.savefig(plot_path, dpi=300, bbox_inches='tight', facecolor='white')
print(f"✅ 综合可视化图表已保存:4_ATT_A_IPTW综合可视化.png")
# 显示图片
plt.close()
return plot_path
# 执行可视化
plot_path = generate_comprehensive_plots(iptw_results, final_covariates, OUTPUT_DIR)
# ======================== 6. 最终报告生成 ========================
def generate_final_report(iptw_results, covariates, output_dir):
print("\n" + "="*60)
print("5. 最终分析报告生成")
print("="*60)
model_data = iptw_results['model_data']
att_results = iptw_results['att_results']
bootstrap_results = iptw_results['bootstrap_results']
weighted_smd = iptw_results['weighted_smd']
truncation_results = iptw_results['truncation_results']
e_value_results = iptw_results['e_value_results']
# 计算共同支持域详细数据
treat_ps = model_data[model_data['treatment']==1]['PS值']
control_ps = model_data[model_data['treatment']==0]['PS值']
min_common = max(treat_ps.min(), control_ps.min())
max_common = min(treat_ps.max(), control_ps.max())
treat_in_common = len(treat_ps[(treat_ps >= min_common) & (treat_ps <= max_common)])
control_in_common = len(control_ps[(control_ps >= min_common) & (control_ps <= max_common)])
# 平衡检验统计
balanced_count = len(weighted_smd[weighted_smd['是否平衡(SMD<0.25)'] == '是'])
balanced_rate = round(balanced_count / len(weighted_smd) * 100, 1)
# 报告内容
report_content = f"""# ATT-A-IPTW主分析报告
**分析日期**: {pd.Timestamp.now().strftime('%Y-%m-%d %H:%M:%S')}
**数据来源**: 数据分析总表.xlsx
**分析方法**: ATT-A-IPTW(处理组:外科,对照组:内镜)
**主要结局**: 影像学缓解率
---
## 一、分析设计与数据概况
### 1.1 研究设计
- **处理组**: 外科治疗({len(model_data[model_data['treatment']==1])}例,{round(len(model_data[model_data['treatment']==1])/len(model_data)*100,1)}%)
- **对照组**: 内镜治疗({len(model_data[model_data['treatment']==0])}例,{round(len(model_data[model_data['treatment']==0])/len(model_data)*100,1)}%)
- **总样本量**: {len(model_data)}例
- **协变量数量**: {len(covariates)}个(VIF<5)
### 1.2 协变量列表
| 序号 | 协变量名 | 变量说明 |
|------|----------|----------|
"""
# 变量说明映射
var_descriptions = {
'lesion_location': '囊肿位置(1:胰头颈、2:胰体尾4:胰周)',
'lesion_max_diameter_mm': '囊肿最大径(mm)',
'walled_necrosis': '包裹性坏死(1:有,2:无)',
'modified_ctsi_score': '改良CTSI评分',
'age_years': '年龄(岁)',
'bmi': 'BMI指数',
'gender': '性别(1:男、2:女)',
'apache2': 'APACHE II评分',
'severe_pancreatitis': '重症胰腺炎(1:有2:无)',
'etiology': '病因分类(1:酒精性等)',
'comorbidity_diabetes': '糖尿病(1:是2:否)',
'comorbidity_hypertension': '高血压(1:是2:否)',
'hyperlipid': '高脂血症(1:是2:否)',
'ascites': '腹腔积液(1:是2:否)',
'portal_htn': '门脉高压(1:是2:否)',
'gallstone': '胆囊结石(1:有2:无)',
'wbc_pre': '术前白细胞',
'smoking_history': '吸烟史(1:是2:否)',
'drinking_history': '饮酒史(1:是2:否)'
}
# 添加协变量表格
for i, var in enumerate(covariates, 1):
desc = var_descriptions.get(var, '未明确说明')
report_content += f"| {i} | {var} | {desc} |\n"
# 继续报告内容
report_content += f"""
---
## 二、ATT-A-IPTW建模结果
### 2.1 倾向得分(PS)模型
- **PS模型类型**: 多变量逻辑回归
- **PS模型AUC**: {round(roc_auc_score(model_data['treatment'], model_data['PS值']), 3)}
- **处理组PS均值**: {round(model_data[model_data['treatment']==1]['PS值'].mean(), 3)}
- **对照组PS均值**: {round(model_data[model_data['treatment']==0]['PS值'].mean(), 3)}
### 2.2 权重统计
| 指标 | 原始权重 | 截断后权重(99分位数) |
|------|----------|------------------------|
| 均值 | {round(model_data['权重'].mean(), 3)} | {round(model_data['截断后权重'].mean(), 3)} |
| 标准差 | {round(model_data['权重'].std(), 3)} | {round(model_data['截断后权重'].std(), 3)} |
| 变异系数 | {round(model_data['权重'].std()/model_data['权重'].mean(), 3) if model_data['权重'].mean() > 0 else 0} | {round(model_data['截断后权重'].std()/model_data['截断后权重'].mean(), 3) if model_data['截断后权重'].mean() > 0 else 0} |
| 最大值 | {round(model_data['权重'].max(), 3)} | {round(model_data['截断后权重'].max(), 3)} |
| 有效样本量(ESS) | {round((model_data['权重'].sum()**2)/(model_data['权重']**2).sum(), 1)} | {round(iptw_results['ess_truncated'], 1)} |
### 2.3 共同支持域验证
- **共同支持域范围**: [{round(min_common, 3)}, {round(max_common, 3)}]
- **总覆盖样本比例**: {iptw_results['common_support_coverage']:.1f}%
- **处理组覆盖比例**: {round(treat_in_common/len(treat_ps)*100,1)}%({treat_in_common}/{len(treat_ps)}例)
- **对照组覆盖比例**: {round(control_in_common/len(control_ps)*100,1)}%({control_in_common}/{len(control_ps)}例)
---
## 三、平衡检验结果
### 3.1 加权SMD汇总(SMD<0.25为平衡)
| 协变量 | 处理组加权均值 | 对照组加权均值 | 加权SMD | 是否平衡 |
|--------|----------------|----------------|---------|----------|
"""
# 添加SMD结果
for _, row in weighted_smd.iterrows():
report_content += f"| {row['变量名']} | {row['处理组加权均值']} | {row['对照组加权均值']} | {row['加权SMD']} | {row['是否平衡(SMD<0.25)']} |\n"
# 平衡检验总结
report_content += f"""
### 3.2 平衡检验总结
- **平衡协变量数量**: {balanced_count}/{len(weighted_smd)}个
- **平衡率**: {balanced_rate}%
- **所有协变量是否达到平衡标准**: {'是' if balanced_count == len(weighted_smd) else '否'}
---
## 四、主要结局效应估计(ATT)
### 4.1 ATT点估计
| 指标 | 数值 |
|------|------|
| 处理组(外科)加权缓解率 | {att_results['处理组加权缓解率(%)']}% |
| 对照组(内镜)加权缓解率 | {att_results['对照组加权缓解率(%)']}% |
| ATT(百分点) | {att_results['ATT(百分点)']} |
| ATT(原始值) | {att_results['ATT(原始值)']} |
| OR值 | {att_results['OR值']} |
| OR值解读 | {att_results['OR解读']} |
### 4.2 Bootstrap 95%置信区间(1000次重抽样)
| 指标 | 95%CI下限 | 95%CI上限 | 是否有效 |
|------|-----------|-----------|----------|
| ATT(百分点) | {bootstrap_results['ATT_95%CI下限']} | {bootstrap_results['ATT_95%CI上限']} | {'是' if not (np.isnan(bootstrap_results['ATT_95%CI下限']) or np.isnan(bootstrap_results['ATT_95%CI上限']) or bootstrap_results['ATT_95%CI下限'] < -100 or bootstrap_results['ATT_95%CI上限'] > 100) else '否'} |
| OR值 | {bootstrap_results['OR_95%CI下限']} | {bootstrap_results['OR_95%CI上限']} | {bootstrap_results['OR_CI是否有效(0.2-5)']} |
| 有效重抽样次数 | {bootstrap_results['有效重抽样次数']}/1000 | - | - |
### 4.3 E-value(未观测混杂效应评估)
- **E-value点估计**: {e_value_results['E_value_点估计']}
- **E-value 95%CI下限**: {e_value_results['E_value_95%CI下限']}
- **解读**: {e_value_results['解读']}
---
## 五、敏感性分析
### 5.1 权重截断敏感性
| 截断分位数 | 截断阈值 | ATT(百分点) | OR值 | OR方向 |
|------------|----------|---------------|------|--------|
"""
# 添加截断敏感性结果
for _, row in truncation_results.iterrows():
report_content += f"| {row['截断分位数']} | {row['截断阈值']} | {row['ATT(百分点)']} | {row['OR值']} | {row['OR方向']} |\n"
# 敏感性分析总结
report_content += f"""
### 5.2 敏感性分析总结
- **截断前后ATT方向是否一致**: {'是' if iptw_results['direction_consistent'] else '否'}
- **主要发现**: {'不同截断水平下效应方向稳定,结果可靠' if iptw_results['direction_consistent'] else '效应方向不稳定,需谨慎解读'}
---
## 六、ATT-A-IPTW适用性判断
### 6.1 验证标准(7项)
| 验证标准 | 是否达标 | 实际结果 |
|----------|----------|----------|
| 1. 共同支持域覆盖>90%样本 | {'是' if iptw_results['common_support_coverage'] > 90 else '否'} | {iptw_results['common_support_coverage']:.1f}% |
| 2. 加权后ESS>50(理想>60) | {'是' if iptw_results['ess_truncated'] > 50 else '否'} | {round(iptw_results['ess_truncated'], 1)} |
| 3. 加权后所有SMD<0.25 | {'是' if balanced_count == len(weighted_smd) else '否'} | {balanced_rate}%变量平衡 |
| 4. Bootstrap 95%CI不包含极端值(OR>5或<0.2) | {bootstrap_results['OR_CI是否有效(0.2-5)']} | OR CI: [{bootstrap_results['OR_95%CI下限']}, {bootstrap_results['OR_95%CI上限']}] |
| 5. 权重截断敏感性:方向一致 | {'是' if iptw_results['direction_consistent'] else '否'} | 方向:{', '.join(truncation_results['OR方向'].unique())} |
| 6. 阴性对照:无关结局ATT≈0 | 待评估 | 数据暂缺 |
| 7. 临床专家:无重大遗漏混杂 | 待评估 | 需专家评估 |
### 6.2 达标统计与结论
- **明确达标项数**: {iptw_results['met_criteria_count']}/7项
- **适用性结论**: {iptw_results['suitability']}
- **建议**: {
'建议使用ATT-A-IPTW作为主分析,补充临床专家评估和阴性对照分析'
if iptw_results['met_criteria_count'] >=5
else '建议使用但需大量敏感性分析,或改用PS匹配等其他方法' if 3<=iptw_results['met_criteria_count']<=4
else '不建议使用,推荐改用PS匹配或其他分析方法'
}
---
## 七、输出文件清单
1. **1_数据缺失值统计.xlsx** - 原始数据缺失值详细统计
2. **2_协变量VIF分析结果.xlsx** - 协变量筛选与VIF检验结果(VIF<5)
3. **3_ATT_A_IPTW综合分析结果.xlsx** - 完整建模结果与验证指标
4. **4_ATT_A_IPTW综合可视化.png** - 6个子图的综合可视化图表
5. **5_ATT_A_IPTW主分析报告.md** - 本报告文件
---
## 八、研究局限性
1. 本分析基于观察性数据,可能存在未观测到的混杂因素
2. 阴性对照分析暂缺,无法完全排除残余混杂
3. 需临床专家进一步评估协变量是否存在重大遗漏
4. 建议补充其他方法(如PS匹配)进行交叉验证
---
*报告生成时间: {pd.Timestamp.now().strftime('%Y-%m-%d %H:%M:%S')}*
"""
# 保存报告
report_path = f"{output_dir}5_ATT_A_IPTW主分析报告.md"
with open(report_path, 'w', encoding='utf-8') as f:
f.write(report_content)
print(f"✅ 最终分析报告已保存:5_ATT_A_IPTW主分析报告.md")
return report_path
# 执行报告生成
report_path = generate_final_report(iptw_results, final_covariates, OUTPUT_DIR)
# ======================== 7. 分析结果汇总 ========================
def summarize_analysis_results(output_dir):
print("\n" + "="*70)
print("6. ATT-A-IPTW主分析结果汇总")
print("="*70)
# 列出所有输出文件
output_files = os.listdir(output_dir)
print(f"📁 分析结果目录:{output_dir}")